

V datové architektuře založené na medailonovém přístupu (Medallion Architecture) představuje Bronze vrstva první stupeň zpracování dat – sem přicházejí surová, minimálně transformovaná data z různých zdrojových systémů. V sérii článků o Fabricu implementujeme datové řešení, kde je Bronze vrstva realizována jako Lakehouse ve Fabricu ve formě delta tabulek a Silver/Gold vrstva jako Data Warehouse plněný přes Dbt (Data build Tool). V rámci projektu nám Azure Data Lake Storage Gen2 (ADLS Gen2) slouží jako fyzické úložiště dat před importem do Bronze vrstvy ve Fabricu.
Azure Data Lake Storage Gen2 (ADLS Gen2) – co to je
Azure Data Lake Storage Gen2 je cloudové úložiště určené pro ukládání velkých objemů dat v rámci platformy Microsoft Azure. Kombinuje vlastnosti Azure Blob Storage a Hadoop Distributed File System (HDFS). To je ideální řešení pro datové jezera a analytické scénáře. ADLS Gen2 podporuje hierarchickou strukturu složek, řízení přístupů na úrovni adresářů a efektivní práci s velkými datovými soubory, například ve formátu Parquet nebo Delta.
V našem případě je ADLS Gen2 využíván čistě jako layer pro ukládání a zálohu dat. Fabric sám o sobě data z tohoto úložiště bude číst a následně data zamergujeme do Lakehouse.
Struktura a organizace zdrojových dat v ADLS Gen2
Při návrhu struktury Bronze vrstvy je klíčové zajistit přehlednost, konzistenci a efektivní práci s datovými partitions. Adresářová struktura, kterou používáme v rámci úložiště ADLS Gen2 vypadá následovně:
/data-lake/
└── 01_bronze/
└── <source_system>/
└── <table_name>/
└── year=<ingestion_year>/
└── month=<ingestion_month>/
└── day=<ingestion_day>/
└── <ingestion_timestamp>data.parquet
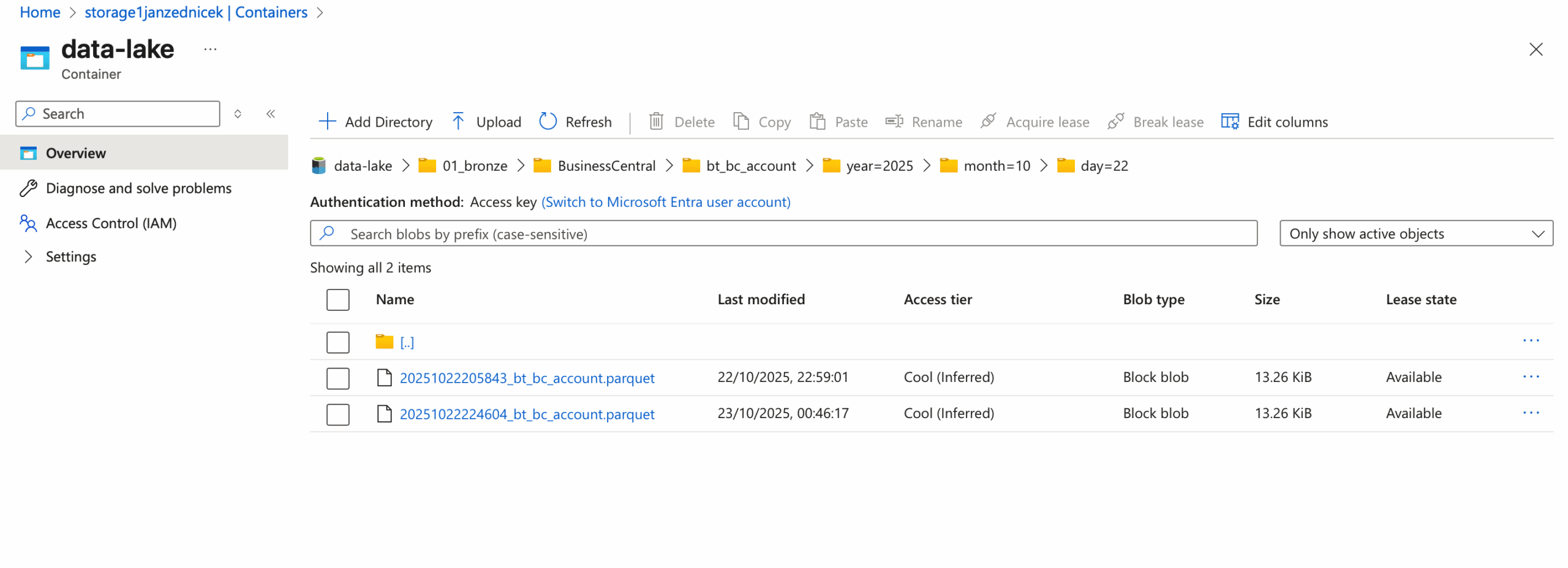
Tento způsob strukturování přináší následující výhody:
- Jasná organizace dat dle zdrojového systému a tabulky.
- Efektivní filtrování a načítání – jednotlivé složky slouží jako partition klíče
- Snadná integrace s Delta Lake a Fabric – adresářové členění se přímo mapuje na partitioning v tabulkách.
Používáním partitions nad delta tabulkami ve Fabricu si budujeme základ pro rychlé a efektivní čtení dat
Datová akvizice přes Azure Data Factory
Přenos dat do Bronze vrstvy probíhá obvykle pomocí pipeline v Azure Data Factory (ADF), což je pro nás hlavní tool pro datovou akvizici.
Typický proces zahrnuje následující kroky:
- Načtení zdrojových dat – například z SQL databáze, REST API nebo blob storage
- Transformace do Parquet formátu – převod dat do sloupcového formátu zajišťuje efektivní ukládání i čtení
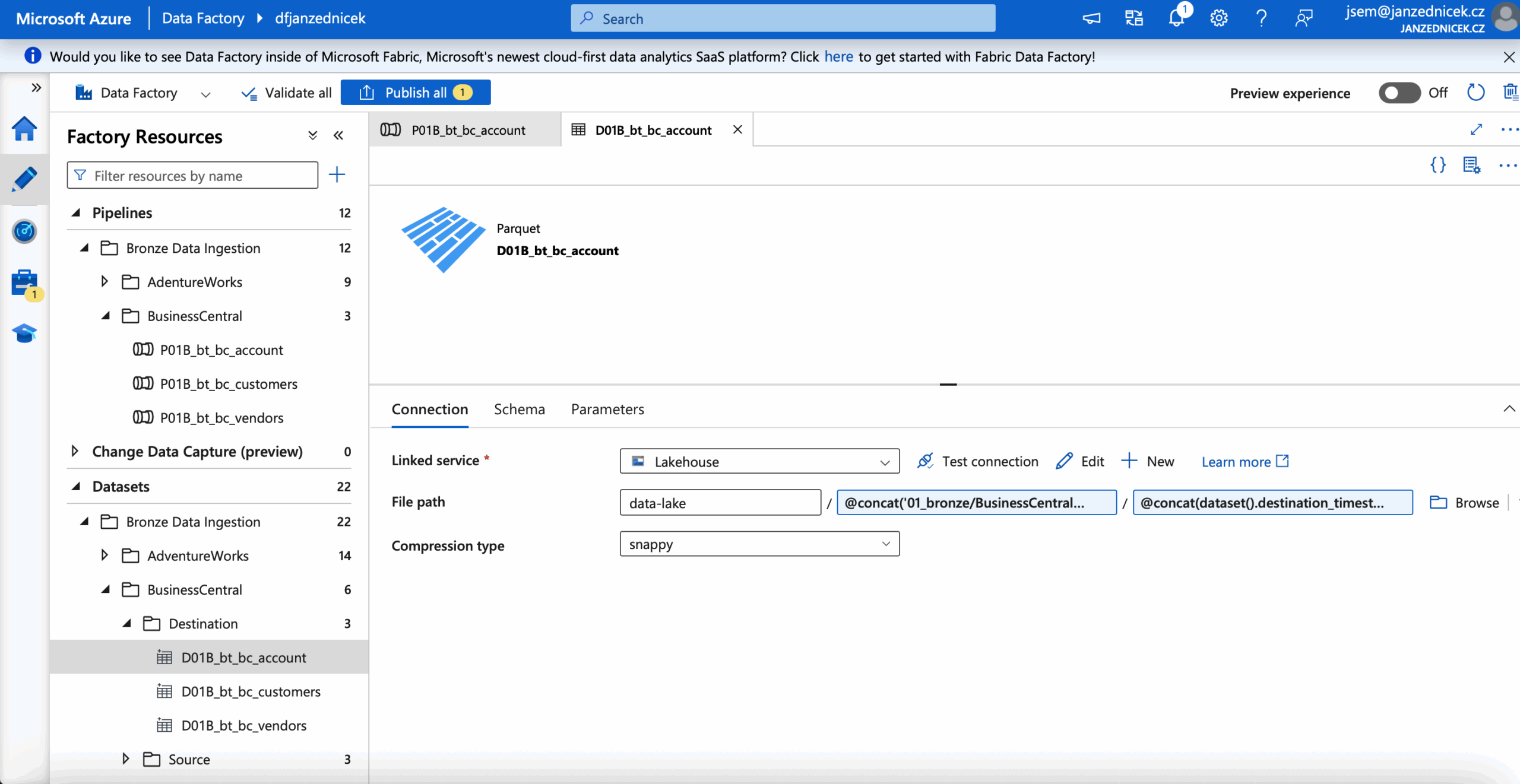
- Zápis do ADLS Gen2 – pomocí dynamického výrazu v ADF se automaticky vytvoří složky podle aktuálního data ingestion:
@concat('01_bronze/BusinessCentral/'
,dataset().destination_table,
'/year=',dataset().ingestion_year,
'/month=', dataset().ingestion_month,
'/day=', dataset().ingestion_day)/
- Validace a audit – možnost uložit metadata o běhu pipeline (počet záznamů, timestamp, stav ingestion) do pomocné tabulky nebo Log Analytics.
A co dál ve Fabricu?
Jakmile jsou data uložena v ADLS Gen2, lze je snadno načítat do Lakehouse ve Fabricu (pomocí shortcuts) a dále zpracovávat. Díky použité adresářové struktuře může Fabric automaticky rozpoznat partition sloupce (year, month, day), což zrychluje čtení dat a následně merge do delta tabulek ve Fabricu. Co nás čeká dále:
- Do založeného Bronze Lakehouse ve Fabricu vytvoříme propojení na ADLS Gen2 data pomocí shortcut abychom mohli parquety číst
- Vytvoříme MERGE notebooky, které si budou podle ingestion date číst data z ADLS Gen 2 a zamergují nám nové soubory do delta tabulek. Tyto notebooky budou připraveny pro orchestraci pomocí pipelines.
- Delta tables v Bronze lakehousu budou zdrojem dat pro Silver a Gold medailony. To už bude zajišťovat dbt (data build tool), který pouštíme přes Azure container app job. Pro volání z Fabricu v rámci orchestrace máme připraven notebook.
Takto připravená architektura tvoří spolehlivý základ pro budoucí Silver a Gold modely, které již pracují s očištěnými a obohacenými daty. Fabric v tomto případě představuje výpočetní vrstvu (Lakehouse, dbt, Delta), zatímco ADLS Gen2 plní roli spolehlivého úložiště.