

V několika předchozích článcích jsem řešil jak nastavit ADLS Gen2 pro ukládání zdrojových .parquet dat a také jak si přes shorcut ADLS gen 2 propojit přímo s Fabric Lakehouse. Pro shrnutí – ve Fabric prostředí tedy máme připraven Bronze Lakehouse a v tomto lakehousu máme vytvořené propojení na parquet data. Nyní je čas na to zajistit plnění naší Bronze vrstvy – delta tabulky jako zdroj pro silver/gold medailony, které budeme později plnit přes dbt.
Delta tabulky jsou hlavní komponentou Fabric Lakehouse, protože poskytují transakční podporu a zajišťují konzistenci dat (ACID). Umožňují aktualizaci, mazání a sledování změn v datech, čímž se minimalizuje riziko nekonzistentních nebo ztracených dat.

Iniciální Vytvoření delta tabulek a systémové atributy
Vytvoření delta tabulky by mohlo vypadat jako na skriptu níže. Zdrojová data (ADLS Gen2) doporučuju doplnit kromě originálních dat (černě) také o systémové informace (viz skript níže) tak, aby každá tabulka měla tuto sadu atributů povinně:
- source_updated_at – datum poslední změny
- source_businesskey – business klíč (přimární klíč záznamu na zdroji) přes který generujeme surrogate keys v dbt
- source_system – kód zdrojového systému je další z atributů přes který generujeme surrogate keys v dbt
- ingestion_date – přes datum akvizice děláme historizace SCD 2
- ingestion_year – delta partition
- ingestion_month – delta partition
- ingestion_day – delta partition
- ingestion_filename – název parquetu
- ingestion_filepath – cesta k parquet souboru
Tyto systémové informace bych považoval za minimum co se týče informací o systémovém původu dat, které nám velmi usnadní následnou další práci u dbt transformací – nebudeme muset později otrocky přepisovat silver dbt template skripty, protože ty nám budou odkazovat na systémové atributy zdrojové tabulky, které budou vždy stejně pojmenovány.
CREATE OR REPLACE TABLE bt_aw_customer
USING DELTA
PARTITIONED BY (ingestion_year, ingestion_month, ingestion_day)
AS
SELECT
CAST(CustomerID AS STRING) AS CustomerID,
CAST(NameStyle AS STRING) AS NameStyle,
CAST(Title AS STRING) AS Title,
CAST(FirstName AS STRING) AS FirstName,
CAST(MiddleName AS STRING) AS MiddleName,
CAST(LastName AS STRING) AS LastName,
CAST(Suffix AS STRING) AS Suffix,
CAST(CompanyName AS STRING) AS CompanyName,
CAST(SalesPerson AS STRING) AS SalesPerson,
CAST(EmailAddress AS STRING) AS EmailAddress,
CAST(Phone AS STRING) AS Phone,
CAST(PasswordHash AS STRING) AS PasswordHash,
CAST(PasswordSalt AS STRING) AS PasswordSalt,
CAST(rowguid AS STRING) AS rowguid,
CAST(ModifiedDate AS STRING) AS ModifiedDate,
CAST(ModifiedDate AS TIMESTAMP) AS source_updated_at,
CAST(CustomerID AS STRING) AS source_businesskey,
"AdventureWorks" AS source_system,
TO_TIMESTAMP(
CONCAT(source.year, '-', source.month, '-', source.day),
'yyyy-M-d'
) AS ingestion_date,
source.year AS ingestion_year,
source.month AS ingestion_month,
source.day AS ingestion_day
FROM parquet.`Files/data-lake/01_bronze/AdventureWorks/Customer` as source;
Založení delta tabulky je jednorázová operace, která se dá udělat buď manuálně nebo se dá zautomatizovat pokud by vám vadila časová investice při zakádání (netrvá to ale dlouho).
Insert Skript pro plnění delta tabulek – přes fabric pipelines
SQL skript nám bude sloužit k tomu, abychom nová data, která se objeví v ADLS Gen2 zapsali do delta tabulek. Aby tato operace netrvala dlouho, tak musíme vymyslet nějaké filtrovací kritérium na straně storage, abychom do delta tabulky neposílali zbytečně mnoho záznamů. Přesně pro tento účet ve zdrojové delta tabulce (viz předchozí kapitola) máme ingestion data atributy a tím pádem jsme pomocí nich schopni ze zdroje rychle identifikovat pouze ta data, která nám chybí.
K automatizaci plnění delta tabulek budeme potřebovat:
- notebook s SQL merge skriptem
- pipeline, která spouští notebook viz 1 (tato pipeline bude následně součástí parent orchestrátoru)
Já již takový notebook mám připraven, tak si to ukážeme:
- Přes task flow navigaci vlezu do prepare delta tables části a zobrazí se nám uložené artefakty

- Otevírám třeba pipeline 01_bronze_deltabt_address – zde mám pouze primitivní volání notebooku obsahující SQL skript pro ukázku

- Double-clickem na notebook se dostávám na kód notebooku v prostředí spark SQL. Tento notebook se bude pouštět v rámci orchestrátoru po datové akvizici.
- Ve WHERE části je vidět, že do vkládáme pouze nová data
- a to pouze data, která byla nějakým způsobem změněna
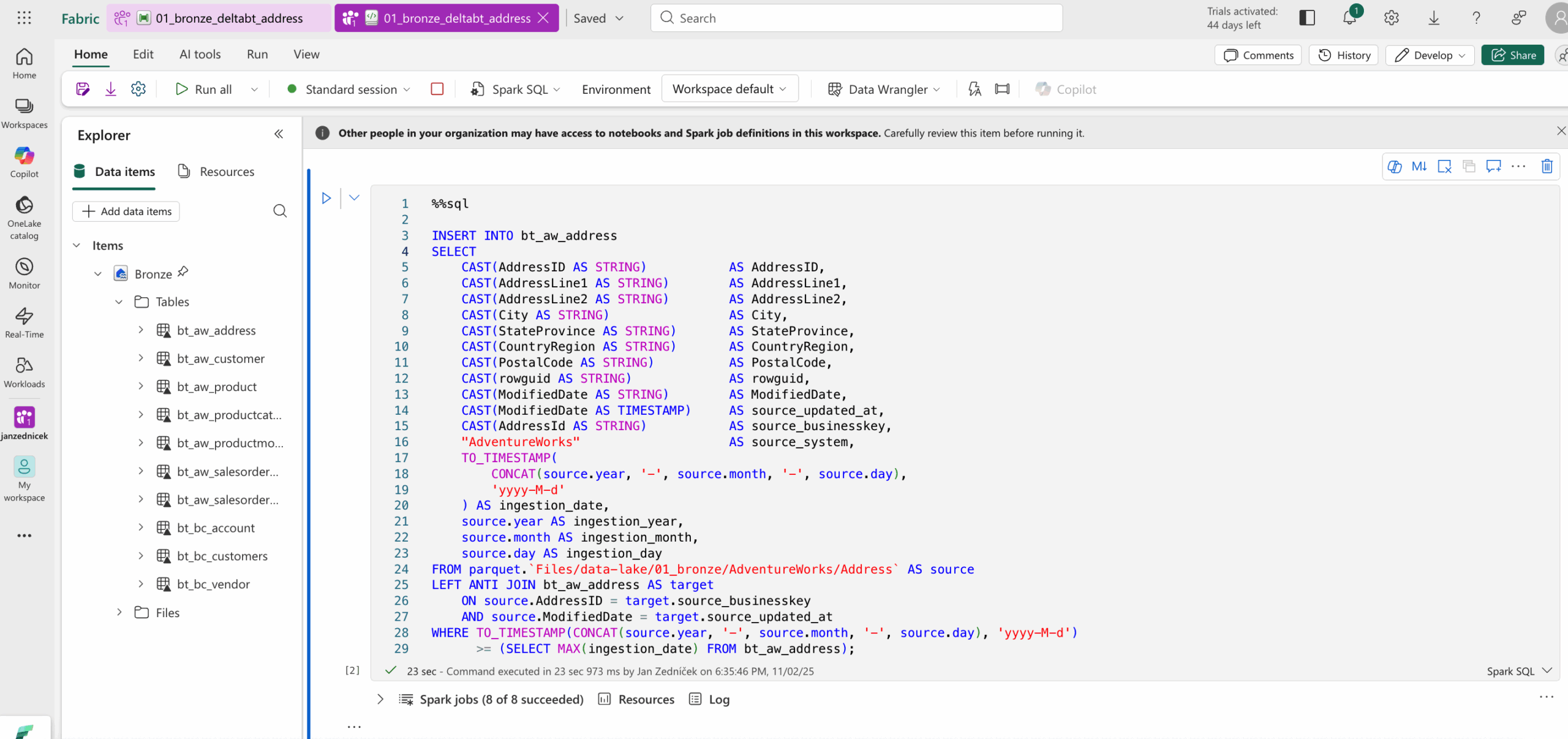
můžeme použít i jednodušší variantu za cenu více záznamů v delta tabulce a to je prostě vložení nových ingestion date ze zdroje s tím, že deduplikaci a filtraci provedeme až v silver vrstvě.
INSERT INTO bt_aw_address
SELECT
CAST(AddressID AS STRING) AS AddressID,
CAST(AddressLine1 AS STRING) AS AddressLine1,
CAST(AddressLine2 AS STRING) AS AddressLine2,
CAST(City AS STRING) AS City,
CAST(StateProvince AS STRING) AS StateProvince,
CAST(CountryRegion AS STRING) AS CountryRegion,
CAST(PostalCode AS STRING) AS PostalCode,
CAST(rowguid AS STRING) AS rowguid,
CAST(ModifiedDate AS STRING) AS ModifiedDate,
CAST(ModifiedDate AS TIMESTAMP) AS source_updated_at,
CAST(AddressId AS STRING) AS source_businesskey,
"AdventureWorks" AS source_system,
TO_TIMESTAMP(
CONCAT(source.year, '-', source.month, '-', source.day),
'yyyy-M-d'
) AS ingestion_date,
source.year AS ingestion_year,
source.month AS ingestion_month,
source.day AS ingestion_day
FROM parquet.`Files/data-lake/01_bronze/AdventureWorks/Address` AS source
WHERE TO_TIMESTAMP(CONCAT(source.year, '-', source.month, '-', source.day), 'yyyy-M-d')
>= (SELECT MAX(ingestion_date) FROM bt_aw_address);
Závěr a testování stažení dat a plnění delta tabulek
Posledním krokem je vytvoření testovací pipeline, která:
- Spustí Azure data factory pipeline, která provede akvizici dat a uloží parquet soubory do ADLS Gen2
- Spuštění notebooku, který vloží stažená data do delta tabulky přes skript skriptem viz výše
