

In a data architecture based on the Medallion Architecture approach, the Bronze layer represents the first stage of data processing – this is where raw, minimally transformed data from various source systems arrive. In the Fabric article series, we implement a data solution where the Bronze layer is implemented as a Lakehouse in Fabric in the form of Delta tables, and the Silver/Gold layers as a Data Warehouse populated via Dbt (Data Build Tool). Within the project, Azure Data Lake Storage Gen2 (ADLS Gen2) serves as the physical data storage before being imported into the Bronze layer in Fabric.
Azure Data Lake Storage Gen2 (ADLS Gen2) – what it is
Azure Data Lake Storage Gen2 is a cloud-based storage service designed for storing large volumes of data within the Microsoft Azure platform. It combines the capabilities of Azure Blob Storage and Hadoop Distributed File System (HDFS), making it an ideal solution for data lake and analytical scenarios. ADLS Gen2 supports a hierarchical folder structure, access control at the directory level, and efficient handling of large data files, for example, in Parquet or Delta format.
In our case, ADLS Gen2 is used purely as a layer for storing and backing up data. Fabric itself will read data from this storage and subsequently merge it into the Lakehouse.
Structure and organization of source data in ADLS Gen2
When designing the Bronze layer structure, it is crucial to ensure clarity, consistency, and efficient work with data partitions. The directory structure we use within the ADLS Gen2 storage looks as follows:
/data-lake/
└── 01_bronze/
└── <source_system>/
└── <table_name>/
└── year=<ingestion_year>/
└── month=<ingestion_month>/
└── day=<ingestion_day>/
└── <ingestion_timestamp>data.parquet
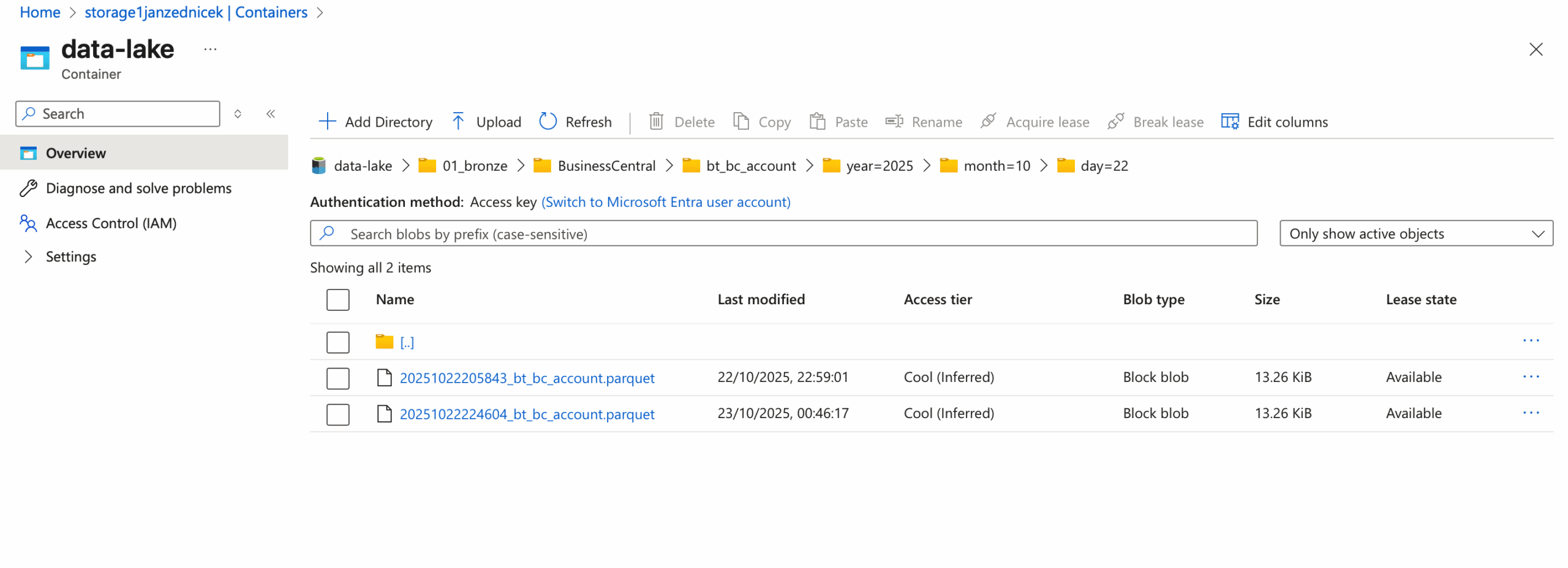
This structuring method brings the following advantages:
- Clear organization of data by source system and table.
- Efficient filtering and loading – individual folders serve as partition keys.
- Easy integration with Delta Lake and Fabric – the folder hierarchy directly maps to table partitioning.
By using partitions over Delta tables in Fabric, we are building a foundation for fast and efficient data reading.
Data ingestion via Azure Data Factory
We perform data transfer into the Bronze layer using a pipeline in Azure Data Factory (ADF), which serves as our main tool for data ingestion.
A typical process includes the following steps:
- Loading source data – for example, from SQL databases, REST APIs, or blob storage.
- Transformation into Parquet format – converting data into a columnar format ensures efficient storage and querying.
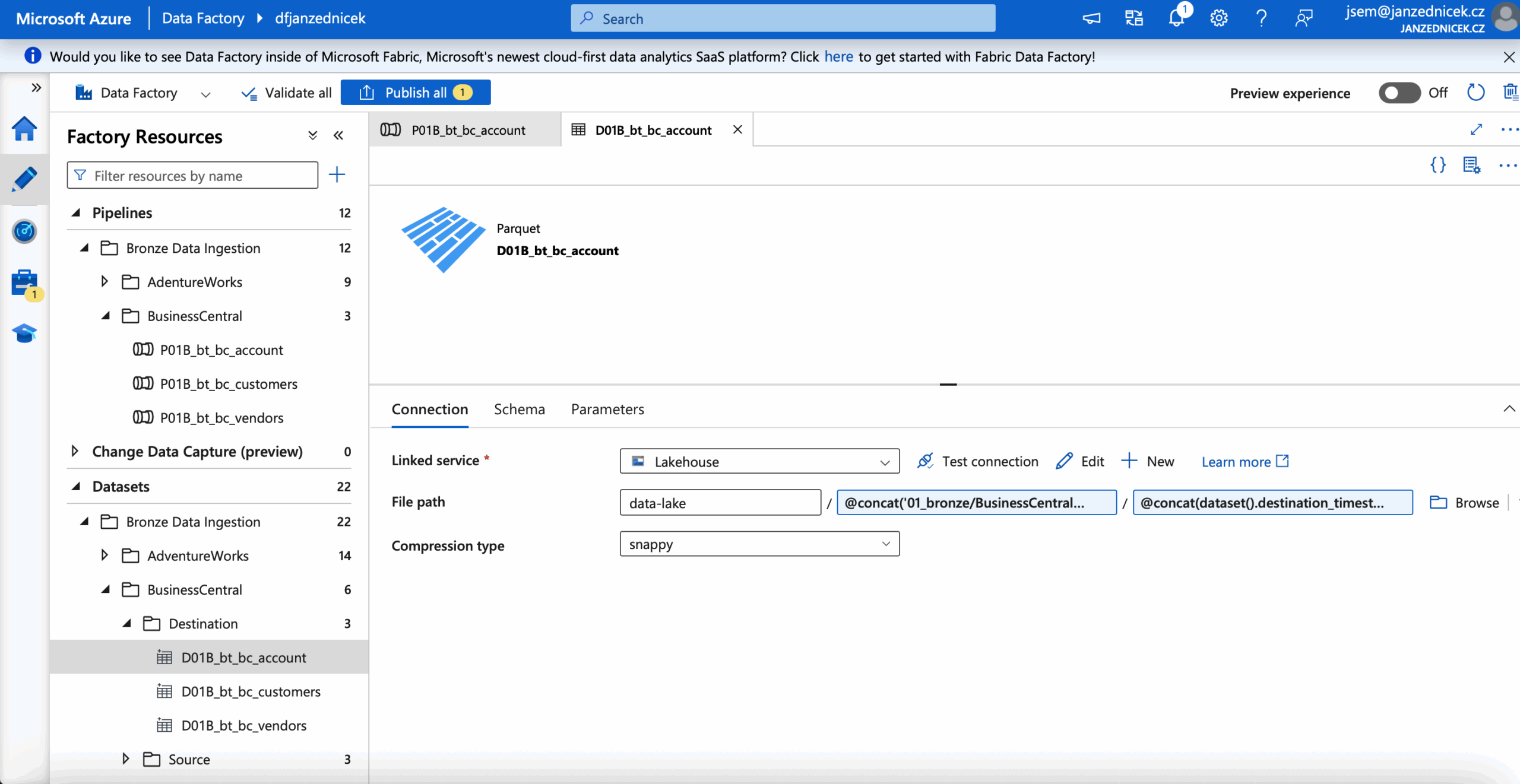
- Writing to ADLS Gen2 – using a dynamic expression in ADF automatically creates folders based on the current ingestion date:
@concat('01_bronze/BusinessCentral/'
,dataset().destination_table,
'/year=',dataset().ingestion_year,
'/month=', dataset().ingestion_month,
'/day=', dataset().ingestion_day)/
- Validation and audit – the option to store metadata about the pipeline run (record count, timestamp, ingestion status) into an auxiliary table or Log Analytics.
What’s next in Fabric?
Once the data is stored in ADLS Gen2, it can be easily loaded into the Lakehouse in Fabric (using shortcuts) and further processed. Thanks to the chosen folder structure, Fabric can automatically recognize partition columns (year, month, day), which accelerates data reading and subsequent merging into Delta tables in Fabric. What’s coming next:
- In the established Bronze Lakehouse in Fabric, we will create a connection to ADLS Gen2 data using a shortcut to allow Parquet file reading.
- We will create MERGE notebooks that, based on the ingestion date, will read data from ADLS Gen2 and merge new files into Delta tables. These notebooks will be prepared for orchestration using pipelines.
- Delta tables in the Bronze Lakehouse will serve as the data source for the Silver and Gold medallions. This will be handled by dbt (data build tool), executed via an Azure Container App job. For orchestration from within Fabric, we have a prepared notebook.
This architecture provides a reliable foundation for future Silver and Gold models that work with cleansed and enriched data. In this case, Fabric represents the compute layer (Lakehouse, dbt, Delta), while ADLS Gen2 serves as the reliable storage layer.