

Minule jsem se rozepsal na téma fuzzy lookupu a v článku jsem dost odbočil od původního zaměření biportalu, totiž BI. Brzy se k BI opět vrátím, ale dnes ještě věnuju článek webu, který jsem si nedávno pořídil. Nemám totiž moc kam jinam psát 🙂 Článek slouží hlavně pro mě jako záznam o aktivitách. Snažím web dostat z problému plynoucích z penalizace od Google. Třeba to někoho bude zajímat…
Informace o Webu
Web má velké trable a chci si tímto článkem udělat časové razítko a shrnout stav webu k dnešnímu dni. Má totiž penaltu od google a nezobrazuje se ve vyhledávačích. Nutno říci, že na něj nebylo cca dekádu šáhnuto a tehdy byly jiné trendy a “optimalizační metody”. Dneska už by taky neprošly třeba daňové optimalizace ala 90. léta že. 🙂
Když jsem si web pořizoval, tak jsem věděl, že má tyto problémy a bral jsem to jako rizikovou investici, ale né zase tak moc – proč? Protože obsahuje kvalitní content a já mám prostě rád kvalitní a jedinečný obsah.
Důvodem je to, že takový obsah žije navěky narozdíl třeba od článků v elektronických médiích, které mají jepičí život (v řádu dnů) nebo recenze mobilního telefonu – model XYZ, který má život v řádů roků – pak je telefon zastaralý a nikdo se o něj nezajímá. Nemoci jsou pořád stejné…
Rozhodl jsem se, že zkusím web opravit sám. Rád se učím nové věci a víceméně jsem seznal, že je web z hlediska SEO v tak špatném stavu, že se toho moc zkazit nedá. Když to nepůjde, SEO šamana můžu najmout vždycky 🙂 Stav webu bych zjednodušeně popsal takto:
Webem je lékařská encyklopedia psaná v anglickém jazyce – beltina.org. Obsahuje přibližně 1400 článků o různých nemocech a anatomii lidského těla. Web vypadal takto.
Aktuálně se návštěvnost pohybuje okolo cca 1500 UIP a to i přes to, že se jednotlivé podstránky webu ve vyhledávání zobrazují POUZE po explicitním zadání adresy webu, jinak smůla. To mě celkem překvapilo.

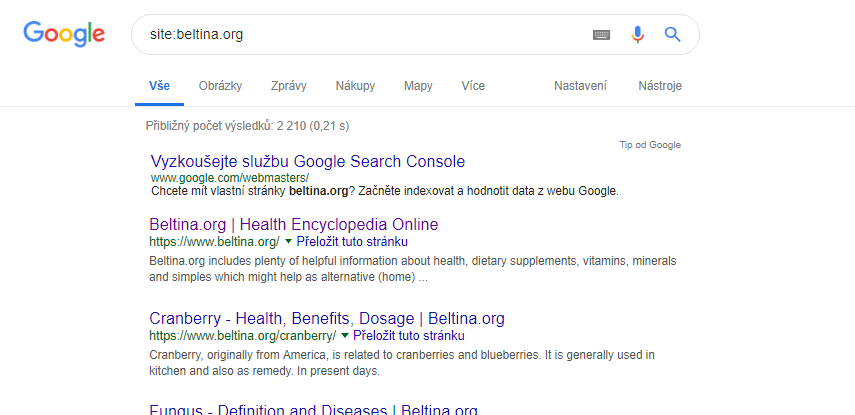
Pokud vezmu úryvek nějakého textu z článku a pokusím se jej vyhledat přes Google, tak to výsledek nevrátí, protože web není zaindexován. Třeba text níže z beltiny google “nezná”:
Proto-oncogenes are the normal genes which contain the genetic code that tells cells which proteins, and how much of them, to produce to direct the cell’s own growth. These proteins, called signaling proteins, act as messengers within the cell.

Doména beltina.org je stará a má domain authority 51, což považuju za pěkné.
Identifikace SEO Problémových Záležitostí Pohledem Laika
Jak jsem zmínil, web má penaltu. Google dává 2 typy trestů – manuální penaltu, o které dá vědět a uděluje ji pravděpodobně člověk z Google, a algoritmickou penaltu, kterou vám udělí výpočetní engine v momentě kdy sezná, že ho šulíte nebo máte nějaký jiný prohřešek (technického charakteru, duplicitní content, pomalá stránka, malware atp).
Algoritmický engine přiřazuje stránce pozici ve vyhledávání na základě mnoha stovek/tisíců veřejných nebo neveřejných faktorů (zpětné odkazy a jejich kvalita/četnost, kvalita a rychlost webu, doména, zabezpečení, atd atd). O této penaltě vědět nedává a vy pouze zaznamenáte propad ve vyhledávání. Pak nezbývá, než si pátrat nebo si pořídit SEO konzultanta, který vám pomůže dobýt zpět ztracené pozice.
Beltina má z nějakého důvodu algoritmickou penaltu a já proto musím web projít a odhadnout kde může být problém.
(1) Skryté odkazy v patičce webu
Řekl bych že toto je asi největší průser, který na webu byl. V patičce webu bylo 18 odkazů na různé weby, které splývaly s pozadím, to google považuje za silně nekalou praktiku. Navíc spousta webu, na které beltina odkazovala již nefungovala nebo měly weby nízké hodnocení.

Penaltu můžete získat za daleko menší prohřešky než je tohle – jako je třeba prodávání odkazů ve velkém nebo třeba odkazování na nekvalitní weby.
(2) Obrázky s “nevhodným” Obsahem
Většina článků měla nějaký náhledový obrázek. Nejsem si jistý jestli všechny obrázky z webu byly zakoupeny nebo z pořízeny fotobank poskytující obrázky volně. Jako neodborník na SEO se neodvažuji spekulovat do jaké míry je Google schopen přiřadit obrázku správného vlastníka a poté potrestat web, který je třeba i omylem využije. Každopádně to není dobré a pokud nemám jistotu, tak takové věci na webu nechci.
Nevhodný obsah – erotický obsah se na webu nevyskytoval, ale je to lékařská encyklopedie a vyskytovaly se tam věci jako obrázky pohlavních orgánů, různé vyrážky a otevřené rány, genetické vady. Prostě věci na které není pěkný pohled. Věřím, že toto třeba google dnes už umí velmi dobře odhalit a potrestat. Zejména třeba pokud nikde na webu není žádné upozornění o takovém obsahu před jeho zobrazením. Opět do odvolání na webu nechci. Obrázky nemocí dávat budu, ale nesmí tam být žádná krev nebo něco co by mohlo působit někomu újmu.
(3) Schéma Interního Prolinkování (pattern)
Interní prolinkování znamená, že když píšete nějaký článek, tak v článku dáte odkaz na jiný článek, který jste napsali dříve – třeba jako já na začátku tohoto článku. Opět by mělo platit, že prolinkování by mělo být přirozené. Beltina je prolinkována opravdu velmi silně. Na příkladu kratší článek, který obsahuje zhruba 20 odkazů na jiné články. To by pole mého názoru až tak nevadilo, kdyby prolinkování bylo děláno přirozeně bez vedlejšího záměru, což se nedělo – doufám že nejsem paranoidní 🙂

Při procházení článků, jsem totiž přišel na to, že články obsahují pravděpodobně pattern. Když jsem poprvé prošel všechny články z první kategorie, opravil linky, nadpisy a dostal jsem se k jejich nadřazené stránce, tak ta skoro žádné odkazy zpět na články neměla a když jo, tak okazovala na články na které vedly shodou okolností odkazy i z jiných nadřazených stránek. Příklad níže. Na obrázku výše byl článek, který obsahoval zhruba 20 odkazů a toto je jeho nadřazená stránka – kategorie “Integumentary system”, ta nemá odkaz ani jeden – asi byl půlvodně tedy záměr takový, umístit se dobře v Google na klíčové slovo dané kategorie – Integumentary system.

Tady to může google jednoznačně vidět jako manipulaci, kdy jednotlivé články předají kousek své “síly” matce a ta jim nic nevrátí zpátky. Matka zase může nakumulovanou sílu předat jiné stránce. Když to tak udělá více mateřských stránek a předají autoritu cíleně pouze na několik stránek, tak tímto způsobem šlo (v době kdy byla stránka vytvořena) docílit toho, že se z pár jednotek stránek na webu staly v očích vyhledávače SUPERSTRÁNKY v top 10 výsledcích na dané klíčové slovo – no a podívejte se kolik lidí měsíčně hledá v angličtině různé variace slova rakovina (cancer) – miliony.
(4) Ostatní Problémy, které Web Sráží
Ty souvisí s tím, že je web prostě starý a nejde s dobou, namátkou:
- absense SSL (https)
- absence mobilní verze – stále více přístupů na weby jsou dnes z mobilu a google umí ocenit mobile friendly weby,
- rychlost webu na mobilech a desktopech
- špatná kategorizace a již zmíněné prolinkování
(5) Keyword Stuffing ??? – Časté Opakování Klíčových Slov
Keyword Stuffing je podvodná SEO praktika a znamená to, že se to v nějakém článku nebo stránce přehání s výskytem klíčových slov. Před mnoha lety (když Google neměl ještě tak dobrý algoritmus) stačilo k dobré pozici ve vyhledávači často opakovat určitá klíčová slova na které se chcete dobře umístit. Třeba:
Kupte si naši zimní bundu XYZ, protože naše zimní bunda XYZ je nejlepší zimní bunda ze všech zimních bund
Tady si nejsem jistý. Na Beltině to takto zjevné jako na příkladu co jsem napsal určitě není. Články jsem jen tak proletěl, ale subjektivně se mi zdá, že některé články obsahují větší procento četnosti klíčových slov než by musely. Těžko říct, kde je hranice a jaké procento klíčových slov by měl text obsahovat. Často se zmiňuje 1,5-3% (ve wordpressu se dá měřit třeba pomocí yoast SEO)
Více zjevných záležitostí jsem neobjevil. Ještě mám jednoho žolíka v rukávu – interní linky jsou UPPERCASEM, což není moc čtivé a asi by bylo lepší to eliminovat, ale řekl bych, že to až takový problém nebude. Zase nevím jak to strejda Google hodnotí.
Vytvoření Nového Webu
Řekl jsem si ,že nejlepší bude vytvořit nový web. Nejsem žádný profík, ale pár webů jsem již udělal v redakčním systému wordpress. Celkově mě web stál cca 150 hodin z čehož drtivou část jsem strávil nad kategorizací a úpravou článků – ještě že mě to baví, profitabilní to asi nebude..nebo jo? Uvidíme podle návštěvnosti :).
(a) Zakoupil jsem kvalitní superrychlou šablonu a web na wordpress převedl

(2) Veškeré výše zmíněné problémové věci jsem odboural
(3) Vytvořil jsem 50 kategorií, dal jim popis. Každá kategorie odkazuje (i) na hlavní článek popisující kategorii (ii) na stránku se seznamem článků v kategorii
(4) Prošel jsem všechny články a každý článek zařadil do kategorie. Některé články jsou ve více kategoriích (maximálně 3 kategorie). Někdo říká že by měly být články pouze v 1 kategorii z důvodů SEO, ale pro mě je rozhodující aby byl web přehledný pro návštěvníka. Pokud je web dobrý pro návštěvníka, je dobrý i pro Google. Jestliže mám totiž článek Lung Cancer (rakovina plic), tak ten prostě patří do Kategorie “Types of Cancer” i do kategorie “Pulmonary Conditions”. Někdo to může hledat v první, někdo v druhé kategorii. Pro tyto účely jsem si založil tagy, které později promažu a upravím. Tagy jsou označeny jako noindex z důvodu eliminace duplicitního obsahu. Kategorie naopak indexuju.
To do: Články budu muset všechny projít ještě jednou a
- optimalizovat nadpisy
- optimalizovat výskyt klíčových slov
- doplnit obrázky
- správně otagovat
No a pak už jen čekat co na to strejda google a jestli mi konečně nějakou stránku zaindexuje a pošle mi prvního organického návštěvníka 🙂