

Správné indexování tabulek v SQL Server je základem pro dobrý výkon databází při dotazování. Chcete-li vytvořit vhodné sql indexy, tak je potřeba pochopit, jakým způsobem SQL Server ukládá data do tabulek/indexů. Neméně důležité je také vědět, jak k těmto údajům následně přistupuje při dotazování.
Jak SQL server organizuje data fyzicky?
V SQL Server je nejmenší jednotkou pro čtení a zápis do db objektů file page, do které SQL Server organizuje data. Každá taková sql file page má 8 KB a vztahuje se k jednomu objektu (například k tabulce nebo indexu). Jednotlivé file pages jsou dále organizovány do Extents (rozsahů), kde každý extent je složen z 8 file pages.
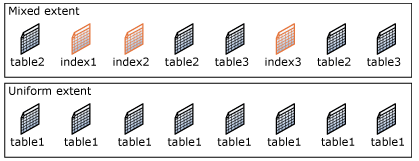
Zdroj: https://technet.microsoft.com/en-us/library/ms190969(v=sql.105).aspx
Data jsou dále na nejvyšší úrovni organizovány do 2 typů souborů, v rámci tohoto článku se zaměřujeme na první z nich (MDF)
- MDF soubory kde leží data
- LDF soubory transakčního logu
Klíč jak pochopit sql indexy? Logická organizace dat v SQL Server
V úvodu jsme zmínili, jakým způsobem se data ukládají fyzicky na disk a nyní se dostáváme konečně k tomu, jak jsou organizována logicky. Jak již bylo popsáno, tak data jsou uložena ve file pages, kterých existují mraky a musí existovat systém jak se v nich SQL server orientuje.
Rychlost SQL dotazů je přímo závislá na tom, jakým způsobem dokáže SQL engine přiřadit jednotlivé file pages k nějaké tabulce, na kterou se dotazujeme. Právě tato rychlost závisí na tom, jak jak jsou tabulky logicky organizovány.
K tomu slouží speciální systémové objekty zvané Index allocation maps (IAM) a každá tabulka má přiřazen minimálně jeden takový objekt. Tyto objekty pracují na principu linkování – linkuje jednotlivé file pages s tabulkami. Podle toho kolik má tabulka IAM rozeznáváme 2 způsoby organizace – Heap a balanced tree
Heap – halda, hromada
Heap je označení pro tabulky, které nejsou logicky organizovány vůbec nijak 🙂 a mají pouze 1 IAM (tzv. first IAM). Můžete si to představit jako byste šli pro knížku do knihovny, která není nijak organizovaná. Museli byste se probrat všemi knihami než byste tu svou našli.
Tabulku tohoto typu dostanete vždy pokud ji založíte bez primárního klíče a bez indexů. Je to jednoduše hromada neorganizovaných file pages. Pokud do takové tabulky provedeme dotaz s podmínkou nebo se pokusíme o JOIN s jinou tabulkou, tak SQL server musí scanovat celou hromadu (heap), každou file page zvlášť => a to trvá hooodně dlouho.

Zdroj: Itzik Ben-Gan, Dejan Sarka, Ron Talmage. Querying Microsoft SQL Server 2012. Microsoft press, Vydání 2012. 752 stran. ISBN 0735666059
Balanced tree
To organizace dat jako balanced tree je jiné kafe. Vždy když nad tabulkou vytvoříte clustered index (např. primární klíč), tak automaticky dochází k organizaci tabulky jako balanced tree. Tato architektura vytváří clustery a proto je hledání záznamů v tabulce mnohem rychlejší. SQL Server nemusí scanovat celou tabulku jako v případě heap, ale hledá po jednotlivých clusterech. Sql indexy tak fungují podobně jako když v knihovně hledáme knižky podle žánrů a autorů.
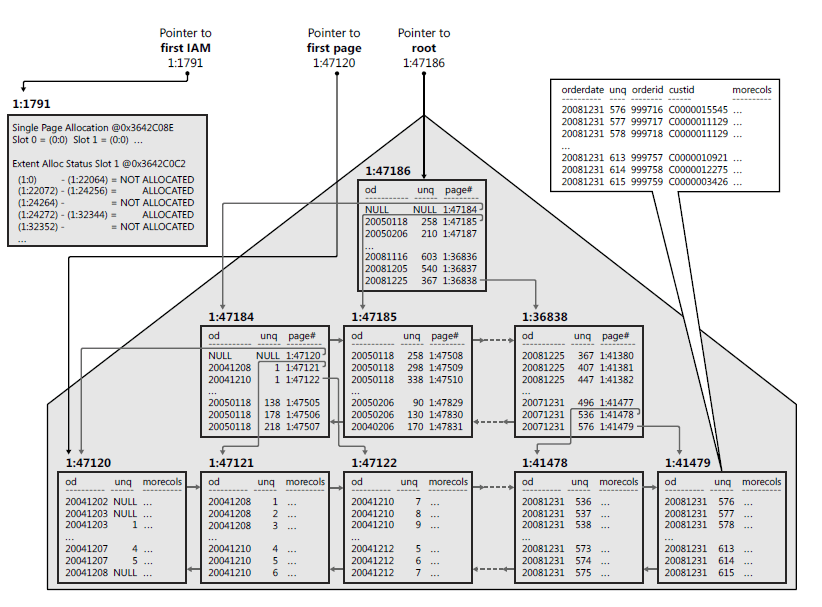
Zdroj: Itzik Ben-Gan, Dejan Sarka, Ron Talmage. Querying Microsoft SQL Server 2012. Microsoft press, Vydání 2012. 752 stran. ISBN 0735666059
V dalších článcích se podívám na fragmentaci indexů a také ukážu skript, jak lze indexy automaticky opravit přes SQL skript
Chapem, ze je to len informacny clanok, ale uz ked sa pouzivaju pojmy, mali by sa pouzit spravne. Posielam info k castiam, ktore boli v clanku nespravne uvedene.
Heap samozrejme mozu mat noclustered indexy a stale to budu heaps. Preto nemusime scanovat vzdy celu heap tabulku.
Heap tabulky samozrejme mozu mat viac ako jeden IAM.
Primary Key je constraint, nie clustered index.
Ak netrafime spravny stlpec, rozdiel v scane clustrovaneho indexu a heap tabule nie je.
Aj B-Tree samozrejme ma IAM, pretoze IAM sluzi hlavne na track space allocation, tak ako je uvedene aj na vasom obrazku.
Ale inac chvalim
Janka
Ahoj Janka, preju uspesny rok 2019 a diky za uzitecny koment. Snazim se byt precizni, ale obcas mi do clanku proklouzne nejaka chybicka 🙂 Zejmena ve vecech kde nejsem tolik silny, jako je teorie. Je tomu tak jak pises, fajn postrehy.
Co se tyce toho primary key, tak tam jsem se spatne vyjadril. Bylo tim mysleno to, že by default je v SQL Server pri vytvoreni primarniho klice vytvoren unique clustered index (jako by byla pouzita konstrukce PRIMARY KEY CLUSTERED). Pri vytvoreni lze ale vynutit option NONCLUSTERED a pokud by to nekdo udelal tak by se cluster index nezalozil.
Mej se a ahoj
Honza
Ahoj,
řešíme ve worku jedno dilema. Máme ohromné datové struktury a hádáme se o typ indexu. Mám tabulku nějakých záznamů, kde klíč je bohužel růstový zleva, představme si VIN auta s rozšířením jeho registrace. Tedy levá strana je náhodná a časově nesortovaná. Prostředek je částečně vzestupný a pravá strana již vzestupná. U nás používáme zbytečně NVARCHAR(35), protože na A-Z0-9 by varchar stačil. Otočit to nejde, protože vstupy jedou takto a nelze změnit strukturu.
Partitioning není řešení, té pravé strany máme hrubým odhadem přes prvních 7 znaků 90+ HEAP (zbytek) kódů.
Kompletní join přes všechny zdroje je asi 25tab s celkovou délkou až 100MB na řádek.
PK má být malý, ale pro defragmanetaci růstový. Tedy stále řešíme, zda použít IDENTITY a tento klíč jako NONCLUSTERED UNIQUE nebo přímo ten klíč jako PK. Denně máme dejme tomu 400.000 nových položek a držíme je 700dní. Na tento PK máme napojené další struktury 1:M, kde M mohou být i desítky. Pro rychlost a bezproblémovost zápisu nepoužíváme FK protože není potřeba ošetřovat import, zda je vše. Různé zdroje data vkládají přes to NVARCHAR() a validitu pak řešíme při zpracování. Lepší sirotek u řádku, než odvolaný import.
Doporučujete tedy ponechat PK Nvarchar(35) nebo použít umělí IDENTITY BIGINT (tabulka se netruncatuje, ale odmazává a data ve skladu jsou již dle bigint PK/FK).
BIGINT bude menší, bez fragmentace, ale s hledáním v NC INDEXU což bude i díky ověřování UNIQUE prostě zdžovat zápis. Naopak dotaz mimo ten klíč na základě indexů bude rychlejší, protože HASH spojení pojede dle vždy skoro 0% fragmentavaného PK a náš klíč v Include už moc zdrojů stát nebude.
Naopak PK jako NVARCHAR() je výhodnější, ale větší, s velkou fragmentací (jedeme 24\7) a noční reindexace jsou na běhu znát. Ale na to napojené jiné indexy už jedou přes fragmentovaný PK. Největší četnost čtení záznamů je za D-1 a index managment přes den neběhá. Data musí mít online pro různé API okamžitě bez zámků apod.
Tedy raději spojovat přes fragmentovaný PK nebo přes NC , pokud 80% dotazů se volá právě přes ten PK na základě nějaké události , ale pár větších sestav párkrát denně přes jiní složené NC_INDEXY. U Automotive třeba období značka či období barva, kde by skoro tříděný PK BIGINT a tento VIN byl pouze jako INCLUDE byl mnohem výkonnější.
Ahoj, nemyslím si, že se to dá bez otestování rozseknout. Ten index bude dycky kompromis a je potřeba to čtení/zápis dát proti sobe na misky vah pro různé scénáře. Taky je potřeba zohlednit jestli ta změna přinese natolik signifikantní dopad, že se do toho vyplatí investovat čas. Většinou bych asi preferoval INT/BIGINT no ale ten tvůj dotaz má hodně proměnných takže si netroufám radit. Proč má ta architektura jako taková tolik tabulek, nedá se to třeba zdenormalizovat?
Ahoj,
je to zdroj pro nalívání dat z externích zdrojů a je již dost normalizované , na jeden klíč je 12 tabulek a zdroj určuje korporát. Tedy možná změna není. Pak si data upravujeme, ale držíme se toho hrozného klíče pak dále a většinou máme denormalizovanoiu verzi na 2tab jen s vybranýma údajema a je to cajk. Ale při rozhodování zda nechat PK jako ten nvarchar klíč či nový umělý jsem nechal původní a i u nás je zda to bylo/nebylo vhodné cca 50:50.
Zápis dat je jen jednou, jen díky tomu datumu na konci a cca několika desetitíců zdrojů se to vkládá nerůstově. Čtení je pak dosti časté a do 24h možná desítky a poté (po noční optimalizaci) spíše náhodně a po kvartálu žádné. Bohužel na hraní, rozjet si to vedle v druhé verzi není čas. Ale i tak dík za info. Ale předpokládám, že u nového řešení bys šel přes umělé PK/FK int/bigint i za cenu nutné převodní tab.