Optimalizace sql dotazů je věčný boj, který začíná už při návrhu architektury databáze a škálování prostředků serveru. Při správném návrhu architektury se můžeme vyvarovat spoustě výkonových problému v budoucnu. V neposlední řadě výkon skriptů můžeme ovlivnit strukturou SQL dotazů a správně nastavenými indexy. Článek rozdělím na 2 hlavnní části:
- Jak optimalizovat pomocí SQL Architektury
- Jak optimalizovat strukturou SQL skriptů
Optimalizace SQL dotazů pomocí architektury databáze a serveru
Níže uvedu z mého pohledu největší drivery z pohledu architektury, které mají na výkon dotazů vliv.
Databázový model
Struktura tabulek a jejich vzájemná kardinalita vztahů má významný vliv na užitnou hodnotu databáze do budoucna. Pokud máme špatně strukturovanou databázi a nevhodně definované vazby mezi tabulkami, tak nám to přinese do budoucna problémy. Skripty budou složitější, budou obsahovat spoustu transformací zpomalující výkon dotazů a údržba takové databáze bude v čase nákladná. Při rozhodování o architektuře databáze se musíme rozhodnout, jestli má být struktura optimalizována pro zápis (aplikace) nebo zejména pro čtení (např. datové sklady). Pro datové sklady volíme modely strukturované do faktových a dimenzních tabulek ve schématu hvězdy (Star schema) nebo Snowflake (vločka) – častější.
Volba datových typů polí v tabulkách
Nad datovými typy se vyplatí přemýšlet. Pokud to lze, tak pro primární klíče volíme datové typy INT nebo BIGINT, protože GUIDY jsou pomalejší při exekuci skriptů a také indexy jsou u GUIDů několikanásobně větší než např u INT. Datové typy (nejen číselné) volíme tak, aby měly co nejmenší velikost). Příklad velikosti číselných datových typů najdete v článku – Číselné datové typy – velký přehled. Optimalizace je v tomto případě zajištěna zejména efektivním joinováním a rychlejšími DML operacemi.
Indexy
Indexy jsou základ. Samozřejmostí je vytvoření primárních klíčů u všech tabulek, který je sám o sobě indexem (cluster index). Kromě toho je potřeba ještě optimalizovat dotazy vytvářením non cluster indexů. Pokud nevíte jak na to, tak si vezměte nějaký složitý skript, který se frekventovaně nad databázi pouští a nechte si vypsat Estimated execution plan. Pokud SQL Engine vidí ve vašem dotazu protor pro optimalizaci, tak v execution planu uvidíte zeleně vypsané upozornění na Missing Index + vliv na zrychlení dotazu v % jestliže se rozhodnete index založit. Skript na založení indexu si můžete vygenerovat přes pravé tlačítko a “Missing index details”. V případě níže nám execution plan doporučuje založit neklustrovaný index a slibuje očekávaný efekt úspory režie ve výši 8 %. Často můžete složitější dotazy (několik joinů + where kritéria) tímto způsobem zrychlit klidně i o 90 %.
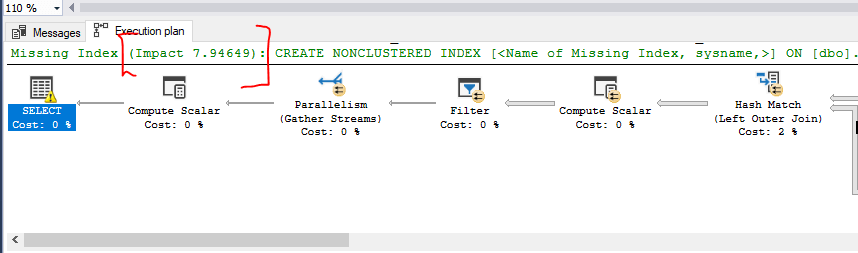
Obecně používejte spíš více štíhlejších indexů (s méně poli) než pár tlustých indexů. Efekt indexace se s počtem polí zahrnutých do indexu snižuje. Pár článků o indexech jsem napsal, najdete je v seznamu níže:
Partitioning (Partitioned Tables)
Tohle vás může dost často zachránit. Partitioning se používá u velmi rozsáhlých tabulek. Jako příklad uvedu tabulku, která loguje přístupy (nebo nějaký ekvivalent). Pokud máme podobnou tabulku, která obsahuje část starších dat, na které se tak často nedotazujeme, stojí za úvahu tento způsob optimalizace. Ten spočívá ve fyzickém rozdělení tabulky (přes filegroups) na několik částí (partitions) – na toto má SQL Server podporu a celý úkon se dá udělat poměrně jednoduše pomocí partition funkcí, kde definujete kritérium pro oddělení dat.
Novější data na která se dotazujeme častěji se mohou také umístit na rychlejší disk a stará na pomalejší např. pomocí nové technologie dostupné od SQL Server 2016 zvané Hybridní Cloud (Strech database). Obě partitions se mohou nechat na stejném disku v jiných filegroups i toto má značný výkonostní efekt – dotazujeme se pouze na 1 filegroup obsahující daleko méně záznamů.
Zjišťuju, že k partitioningu nemám na blogu žádný článek s návodem, tak to musím honem napravit.
Škálování a konektivita serveru
Vždy se najde prostor pro optimalizaci výkonu, který nezahrnuje HW škálování. Pokud ale cítíte, že prostoru pro optimalizaci už je málo a není dostatečně efektivní se takové optimalzaci věnovat, tak se poraďte se svým server administrátorem. Možná společně dojdete k názoru, že má smysl alokovat dodatečné prostředky na váš virtuální server (procesory, RAM, disk space pro indexy).
Optimalizace SQL dotazů vhodnou strukturou dotazu
Níže uvádím pár příkladů a doporučení k optimalizaci. Obecně ale platí, že než pustím skript, tak si ho 2x přečtu a popřemýšlím jestli se nedá zjednodušit a zkvalitnit s ohledem na výkon SQL dotazu. Dvojnásob to platí u frekventovaných skriptů. U těch si skript po sobě projděte 4x a vytvořte na něj indexy :). Tak jdem na to…
Dotazujte se na konkrétní sloupce v tabulce
Používejte místo SELECT * konkrétní sloupce v tabulce, které se chystáte použít. Pokud provádíte dotaz, který slouží k tomu abyste se v tabulce zorientovali (např. potřebujete vidět seznam sloupců), tak použijte klauzuli TOP – např.
SELECT TOP 10 <sloupce>FROM <Tabulka>
Minimalizujte používání funkcí ve WHERE klauzuli a už vůbec ne ve FROM
S ohledem na Logické zpracování SQL dotazu je vhodné nepoužívat přílis funkce ve WHERE nebo FROM. Klauzule FROM totiž dotaz logicky zpracovává jako 1. a klauzule WHERE jako 2. Důsledkem je to, že jsou funkce aplikovány na všechny záznamy v tabulce, což výkonu neprospívá. Nechytne se ani index nad polem v podmínce a dochází k full table scan.
Nejoinujte tabulky kartézským součinem, používejte inner join
Nepoužívejte joiny v tomto formátu:
SELECT <Sloupec_1>, <Sloupec_2>FROM <Tabulka_1>, <Tabulka_2>WHERE <Tabulka_1>.ID = <Tabulka_2>.ID
Dotaz je zpracován tak, že je nejprve proveden kartézský součin CROSS JOIN (FROM se zpracovává jako 1. klauzule) a až poté jsou data omezena ve WHERE (zpracovává se jako 2.) – viz článek o logickém zpracování dotazu. Pokud má tabulka 100 000 záznamů, tak kartézským součinem vznikne 100 000 * 100 000 záznamů a pak jsou data omezena, to je samozřejmě neefektivní a je na místě optimalizace dotazu. Místo toho používejte:
SELECT <Sloupec_1>, <Sloupec_2>FROM <Tabulka_1> INNER JOIN <Tabulka_2> ON <Tabulka_1>.ID = <Tabulka_2>.ID
Pracujte efektivně s Wildcards a operátorem LIKE
Procházení string řetězců je jednou z výkonově nejnáročnějších operací. Neefektivní dotaz do tabulky pomocí LIKE s použitím wildcards vypadá třeba takto:
SELECT <Sloupec_1>, <Sloupec_2_String>FROM <Tabulka_1>WHERE <Sloupec_2_String> LIKE ('%ABC%')
Neefektivní je proto, že wildcard % máme na obou stranách stringu, který hledáme v řetězci. Než wildcard použijete, tak se zamyslete, jestli nejde patern vymyslet lépe, například takto:
SELECT <Sloupec 1> FROM dbo.Tabulka WHERE <Sloupec1> LIKE '__ABC%'
Druhý dotaz bude daleko efektivnější z pohledu optimalizace, protože definujeme, že string ABC se nachází na 3-5 pozici zleva a prohledáváme tedy pouze pravou část. Jak používat wildcards se můžete dočíst tady – LIKE operátor s Wildcards.
Minimalizujte ORDER BY pokud to není potřeba
ORDER BY je velice drahá operace a pokud to není nutné, tak ji zbytečně nevyužívejte
{kind=link}