

Potřebovali jste někdy mezi sebou porovnat 2 seznamy a otestovat je na duplicity? Nejjednodušším způsobem jak něco podobného v excelu udělat je využít standardních funkcí jako je například SVYHLEDAT (vlookup). Někdy se nám ale může stát, že chceme porovnat 2 seznamy, kde se vyskytují v jednom z nich překlepy, tady přichází na řadu Fuzzy lookup (ke stažení zde).
Typickým příkladem je např. ručně vedená evidence (např. lidí, firem) v excelu. Do této evidence chceme postupně doplňovat další záznamy. Před jejich vložením si ale chceme ověřit, jestli se data, která chceme do seznamu vložit už v seznamu nevyskytují a to i v případě, že chceme do seznamu přidat záznamy, kde existuje riziko překlepů.
Příklad Fuzzy lookup v excelu
Mějme seznam viz. níže (představte si řádově tisícovky položek), ve kterém evidujeme seznam společností a jejich webové stránky. Seznam chceme udržovat samozřejmě bez duplicit a postupně jej rozšiřovat o nová data. Před každým vložením se chceme přesvědčit jestli se společnost, kterou do seznamu chceme přidat, s seznamu už nenachází
Seznam vypadá takto:

Do seznamu chceme přidat další společnosti. Připravil jsem seznam kandidátů na vložení do evidence tak, že jsem si z hlavního seznamu pár společností zkopíroval a u některých záměrně udělal překlep (červeně). Projedeme seznam fuzzy lookupem a uvidíme, jestli odhalí, že vlastně společnosti v seznamu už jednou máme.

Pokud bysme duplicity hledali například na základě svyhledat, tak vzhledem k překlepům u společností Chevron, AFLAC, Charter Communications a Coca- cola bychom tyhle společnosti vyhodnotili jako nové což není pravda. S odhalením překlepů pomůže právě fuzzy lookup.
1) Nainstalujeme si Excell addin z webu microsoft a po instalaci se vám v Excelu objeví nová záložka “Fuzzy lookup”

2) Oba seznamy si označíme jako pojmenovanou oblast nebo si seznam naformátujeme jako tabulku. V Opačném případě nebude možné se na oblast ve fuzzy lookup odkázat. Následně oba seznamy přidáme do fuzzy lookup oblasti. Left table jako tabulku s daty, která chceme přidat a right table jako tabulku se seznamem. Vsechny sloupce, které se nám potom objeví v sekci Left/right columns označíme a klikneme na ikonu. Tím nastavíme co se má vůči sobě porovnávat a klikneme na GO
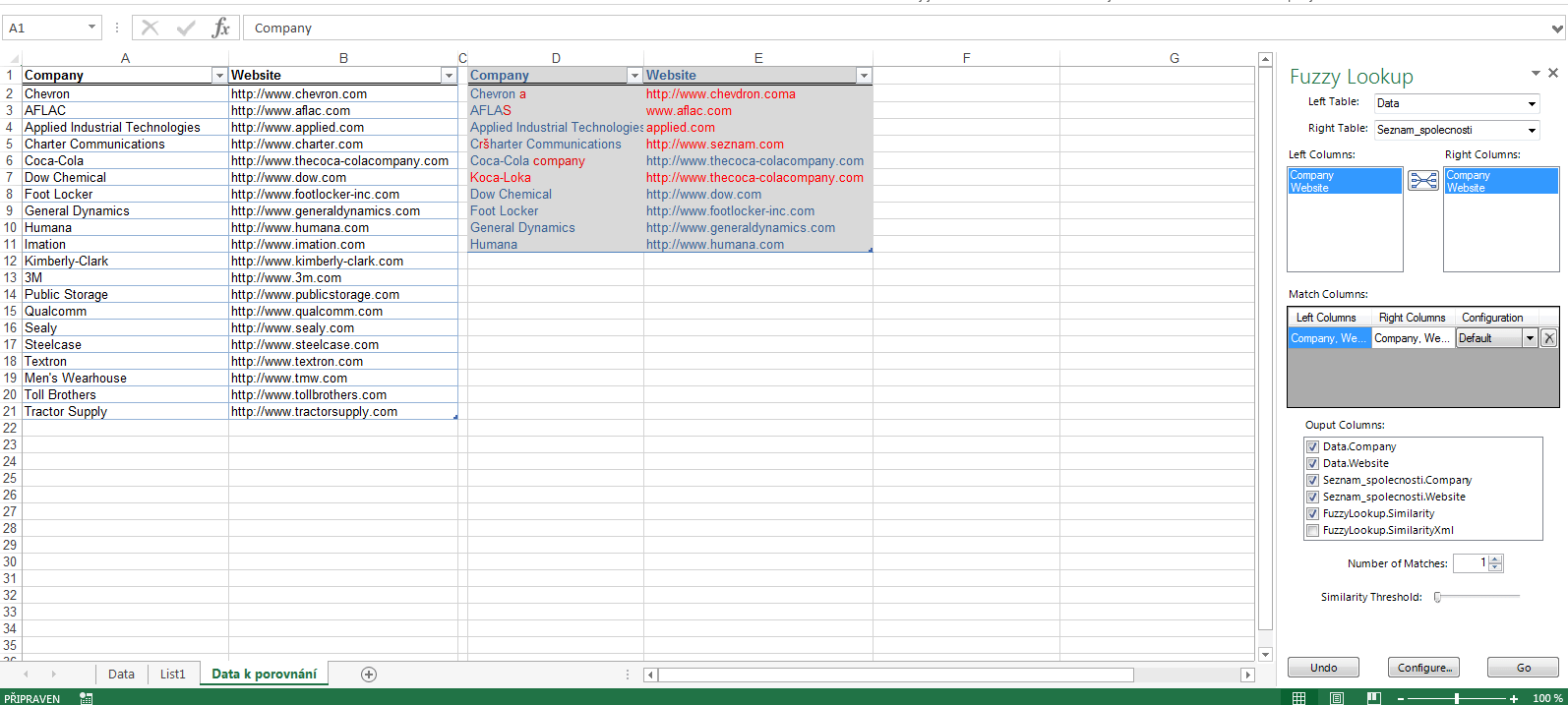
3) Výsledkem je tabulka, která popisuje do jaké míry jsou 2 seznamy podobné. Sděluje nám to přes číslo tzv. Similarity, které se pohybuje v rozmezí 0 – 1. Čím blíže je číslo 1, tím jsou dané položky obou seznamů podobné (1 znamená naprostou shodu).
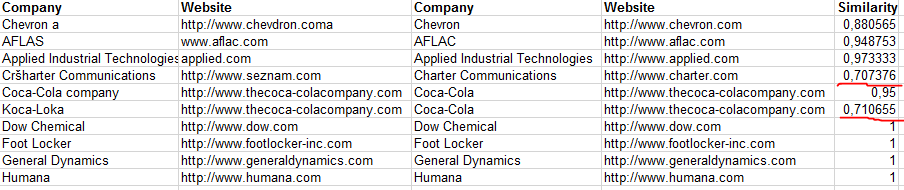
Vyhodnocení a interpretace výsledků fuzzy lookup
Všechny položky jsou duplicitní protože mají vysokou míru shody a do našeho seznamu bychom tedy nevložili žádný záznam:
- Similarity = 1 znamená naprostou shodu
- Similarity >= 0,8 znamená, že společnost a webová stránka v seznamu už existují s tím, že se pokoušíme vložit společnost znovu s překlepem (což sedí)
- Similarity <0,8 tady už je míra podobnosti nižší, ale je stále vysoká. V našem případě jde o Charter Communication kde je chyba v názvu společnosti a v adrese webu. Druhou společností je Koka-Loka, která má stejnou webovou adresu a jiný název. Fuzzy lookup vyhodnotil, že existuje vysoká pravděpodobnost, že jde o duplicitu na základě shody webové adresy.