

Microsoft Fabric 1 představuje sjednocenou SaaS platformu, která integruje komponenty tzv. moderního datového skladu. V rámci jedné platformy je tak možné pořešit ukládání přes artefakty (Lakehouse/DWH), výpočetní prostředky (Spark/Polaris) a nástroje pro orchestraci datových toků. Fabric architektura poskytuje také nástroje pro transformační část (třeba spark), které lze napsat a následně orchestrovat v rámci Fabricu jako takového.
Někdy se ale nechceme uvrtat do vendor locku daného toolu a chceme určitou modularitu řešení. Kritické části jako transformace a zdrojová data mít vytaženy venku (ADLS, dbt) pro snadnou zmigrovatelnost jinam (kdyby šlo do tuhého třeba v pricingu). Dbt v tomto směru nabízí řadů výhod (nejen protože to je open source) a já se v rámci série článků o Fabricu rozhodl právě pro tento tool jako nástroj pro silver a gold medailony. Takže tím pádem to musím trochu vysvětlit.
Role dbt ve Fabricu
dbt (Data Build Tool) plní roli transformačního jádra v ELT modelu (Extract, Load, Transform). Místo toho, aby dbt přesouvalo data (což je úloha Data Factory), zaměřuje se výhradně na T – Transform část. dbt aplikuje principy datového inženýrství – verzování, modularizaci a testování. Tím je zajišťěna robustnost celého transformačního procesu a jeho snadná údržba.
V mém projektu využíváme dbt pro řízení postupu dat skrze Medailonovou Architekturu (Bronze, Silver, Gold). Bronze je u nás ve Fabric reprezentována jako Lakehouse se shortcuts na Azure Data Lage Storage Gen 2 2 parquety s následnou materializací do Delta tabulek. Tyto delta tabulky v Lakehouse jsou pro nás zdroj dat a následně si dbt přebírá další logiku výpočtů silver a gold vrstvy.
O dbt jsem psal dříve v kategorii dbt – je tam nějaké základní představení, jak to rozchodit, jak nakonfigurovat connectiony apod.
Medailonová Architektura: Logické Rozdělení Dat
Medailonový vzor je doporučeným designovým standardem pro Lakehouse systémy. Zajišťuje atomicitu, konzistenci, izolaci a odolnost (ACID) dat na všech úrovních což jsou základní předpoklady pro funkční datové řešení. Každá vrstva má přesně definovanou odpovědnost a minimální požadavky na kvalitu dat.
Malá vsuvka jsou to jenom nová slova pro něco co existuje už dlouho – pro starší dataře se nejedná o nic jiného než fancy buzzwordy pro a) Landing (Bronze), b) Stage (Silver), c) Sémantický model/datamart (Gold).
dbt jako Transformační Motor ve Fabric
Pro efektivní běh transformačních dbt modelů je klíčové pochopení interakce mezi dbt a výpočetním prostředím Fabric.
Konektivita, Výkon a bezpečnost (SQL Endpoint)
- Adaptér dbt: Pro připojení k Fabric se používá dbt-fabric adaptér (odvozený od dbt-spark). dbt se nepřipojuje k Spark clusteru přímo, ale využívá SQL Endpoint Lakehouse pro odesílání SQL dotazů.
- Engine Polaris: SQL dotazy generované dbt jsou zpracovávány enginem Polaris (vysoce výkonný engine pod Fabric). Tato architektura umožňuje dbt spouštět robustní operace jako CREATE TABLE AS SELECT nebo složité příkazy, které jsou optimalizovány pro Delta formát.
- Autentizace SPN: Jak uvidíme v následujících dílech, naše produkční prostředí vyžaduje ověřování pomocí Service Principal (SPN) namísto uživatelského jména a hesla. Toto je kritické pro CI/CD pipeline a bezpečnost. To bude nastaveno v konfiguračních souborech dbt
Modularizace a DAG (Directed Acyclic Graph)
Jádrem metodiky dbt a jeho největší síla je modularizace transformací. Každý krok transformace v rámci medailonové architektury je samostatný SQL soubor (model).
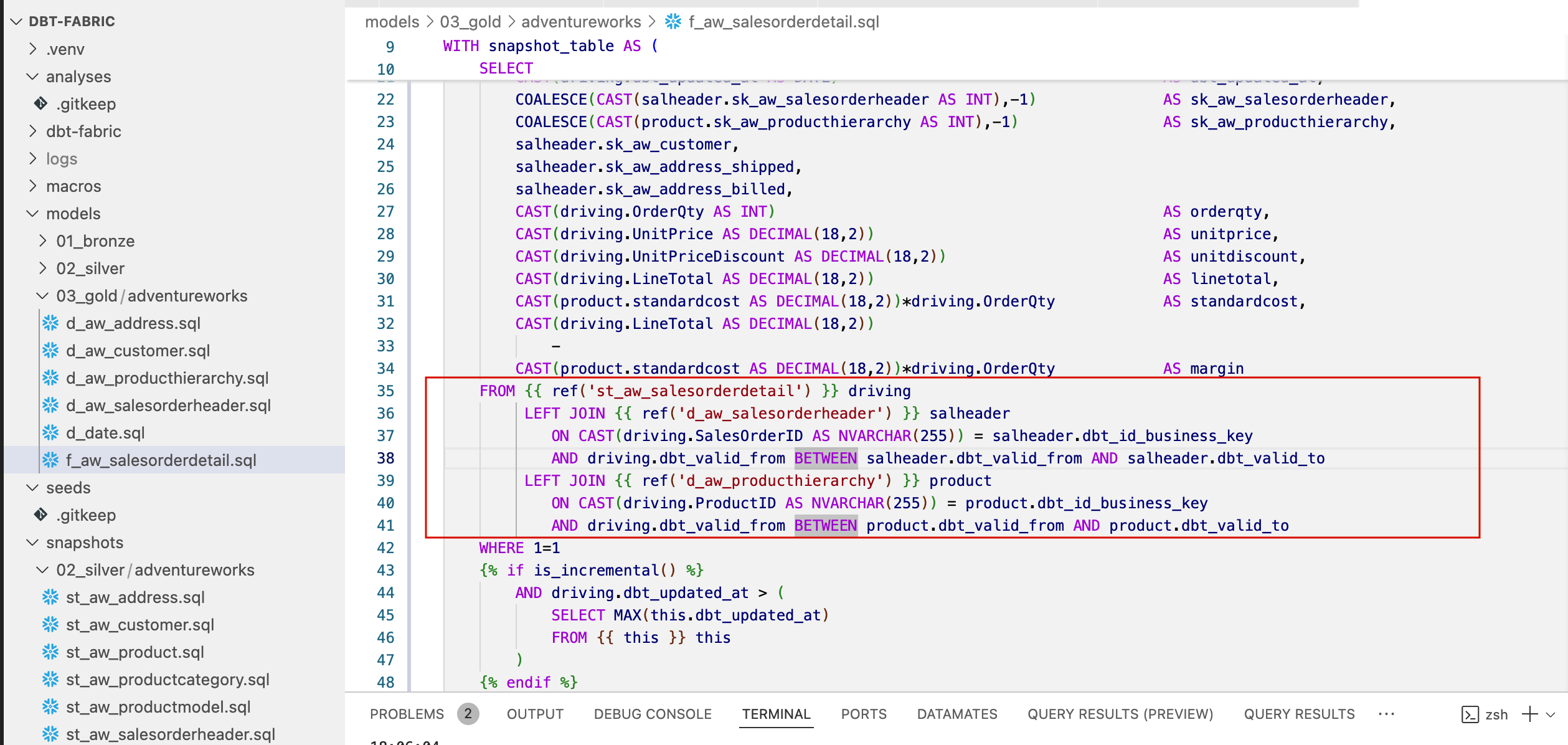
- Závislosti: Závislosti mezi modely (např. Silver model závisí na Bronze modelu nebo jak na sobě závisí jednotlivé tabulky v gold vrstvě) jsou definovány pomocí JINJA makra {{ ref(‘nazev_modelu’) }} viz. obrázek níže.
- Vytváření DAG: dbt automaticky analyzuje tyto reference a sestavuje DAG – acyklický graf. Při spuštění (dbt run) dbt zajistí, že modely jsou spouštěny ve správném topologickém pořadí. To odstraňuje potřebu psát složité kódy pro řízení toku dat v tradičních ETL nástrojích. Díky tomu můžeme spustit celý model a závislosti pomocí jednoho příkazu z terminálu. Závislosti se pořeší samy. Je potřeba akorát pohlídat počet jader, který umožníme dbt využít k paralelizaci na cílovém výpočetním enginu – nastavíme v konfiguraci.
Řízení Inkrementality a Historizace
Jedním z největších technických přínosů dbt ve Fabric Onelake je efektivní práce s datovými změnami:
- Inkrementální Modely: V Silver a Gold vrstvách dbt umožňuje definovat modely jako materialized=’incremental’. Zde dbt využije logiku is_incremental() makra, aby omezilo čtení ze zdroje pouze na nová nebo změněná data. Toto radikálně snižuje výpočetní čas a spotřebu Fabric Capacity (CU).
- Historizace (SCD Type 2): Pro sledování změn klíčových dimenzí (např. zákazník, produkt) dbt pracuje s konceptem Snapshots. Snapshot funkcionalita generuje tabulky, které pro každý záznam zaznamenávají interval platnosti (dbt_valid_from a dbt_valid_to), což je jádro implementace SCD Type 2 pro dimenzní tabulky. Pro velké faktové tabulky budeme používat jiný přístup neboť snapshot metoda dělá can celé zdrojové delta tabulky, což nechceme.
Závěr
Medailonová architektura spojená s dbt metodikou poskytuje robustní základ pro náš projekt pracující se sample daty AdventureWorks. Využitím Fabric jako silného výpočetního a úložného backendu a dbt jako agilního transformačního frontend nástroje zajistíme, že naše data jsou spolehlivá, testovatelná a připravená pro business reporting.
Reference
- Microsoft documentation, Microsoft Fabric [on-line]. [cit. 2025-10-21]. Dostupné z WWW: https://www.microsoft.com/en-us/microsoft-fabric
- Microsoft documentation, Azure Data Lake Storage Gen2 [on-line]. [cit. 2025-10-21]. Dostupné z WWW: https://learn.microsoft.com/cs-cz/power-query/connectors/data-lake-storage