SQL Server nabízí 3 druhy recovery modelu databází – simple recovery model, full a bulk-logged. Recovery model je způsob, jak SQL Server nakládá se transakcemi a transakčním logem a jak tyto data ukládá nebo neukládá. To ve finále ovlivňuje možnosti, které máme při obnovení dat ze zálohy. Recovery model se nastavuje nad určitou databází a každá databáze může mít pouze 1 recovery model. Napříč SQL instancí ale mohou mít různé databáze různé recovery modely.
Simple recovery model
Každá databáze má minimálně 2 soubory – master file (.mdf) ve kterém jsou ukládána data a logovací file (.ldf) kde leží transakční log. Pokud nad určitou databází provedeneme full nebo differential sql backup (zálohu), tak zálohujeme .mdf soubor. V tomto případě jsme schopni data obnovit pouze do okamžiku takové poslední zálohy. V případě tohoto typu recovery modelu můžeme udělat pouze tyto 2 typy záloh. Zálohu transakčního logu provést nemůžeme a vystavujeme se tedy tak riziku, že příjdeme o data od poslední FULL nebo DIFF zálohy. Siple recovery po každé transakci log vyčistí a neumožňuje nám tedy vytvořit restore point.
V některých situacích ale klidně raději volíme právě simple recovery model, protože nám to nevadí – naše data mohou být lehce reprodukovatelná, naše databáze je neprodukční nebo pro to existuje jiný důvod.
Jak funguje transakční log v Simple recovery modelu?
Pokud máme nad databází zvolen Simple recovery model, tak data z transakcí nejsou v .ldf souboru trvale ukládána. Neznamená to ale, že transakce v tomto souboru nejsou dočasně…jsou. Při spuštění transakce se transakční log ukládá a čeká až transakce doběhne do konce. Tento způsob chování umožňuje data rollbacknout v případě kdy je transakce přerušena – abychom o data nepřišli.
Např děláme update a uprostřed transakce klikneme na cancel – data se během update operace nad tabulkou ukládala do transakčního logu, aby bylo možné následně na žádost uživatele o zrušení data obnovit do původního stavu.
Znamená to tedy, že se i v případě simple recovery modelu musíme starat o údržbu (shrink) .ldf souboru na rozumnou velikost, aby nám moc nebobtnal. Pokud provedeme nějakou náročnější operaci nad několika miliony záznamů, tak nám pravděpodobně ldf file pěkně nakynul a měli bychom jej shrinknout. Já to dělám tak, že shrink logovacích souborů mám nastaven v daily maintenance plánu.
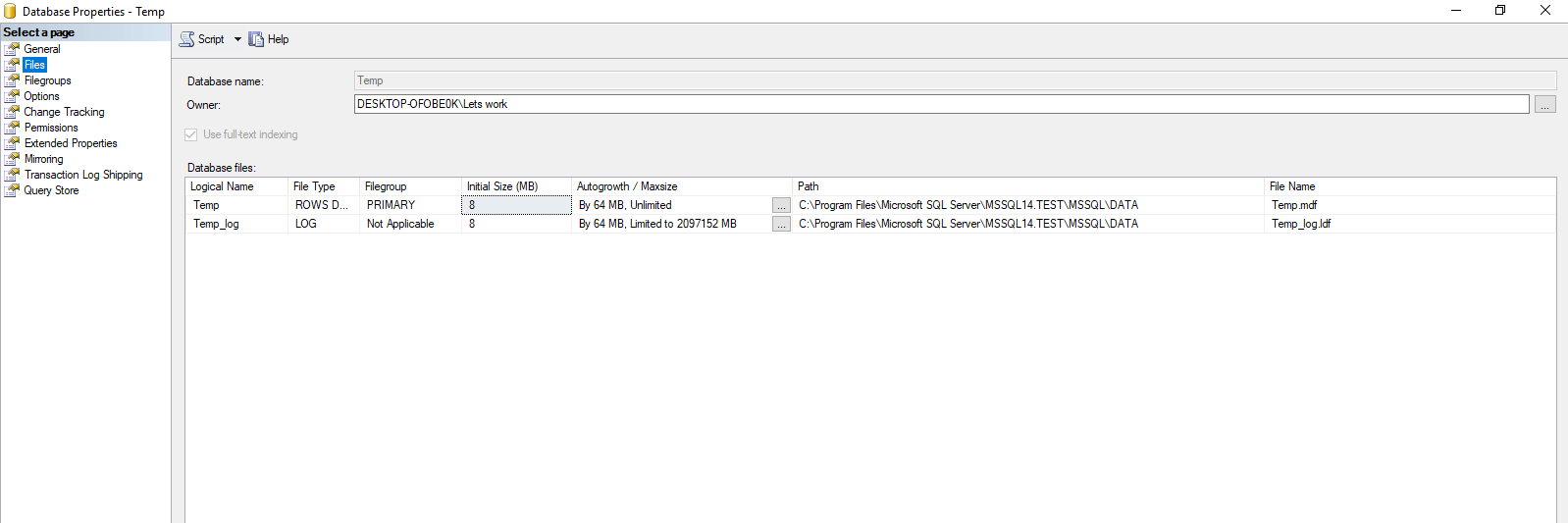
Příklad: Mějme databázi Temp, která má 2 soubory .mdf a .ldf oba o velikosti 8MB. Recovery model nastaven jako SIMPLE
Založím tabulku s BEGIN TRAN a do ní vložím 100000 záznamů
Celé vložení obalím transakcí BEGIN TRAN
CREATE TABLE [dbo].[Test_Transakcni_Log] (
[Cislo] INT NOT NULL
);
BEGIN TRAN
DECLARE @Cislo AS INT = 1
WHILE @Cislo < 100000
BEGIN
INSERT INTO [dbo].[Test_Transakcni_Log] ([Cislo])
VALUES (@Cislo)
SET @Cislo = @Cislo + 1
END;
Po založení tabulky s BEGIN TRAN máme čekající transakci
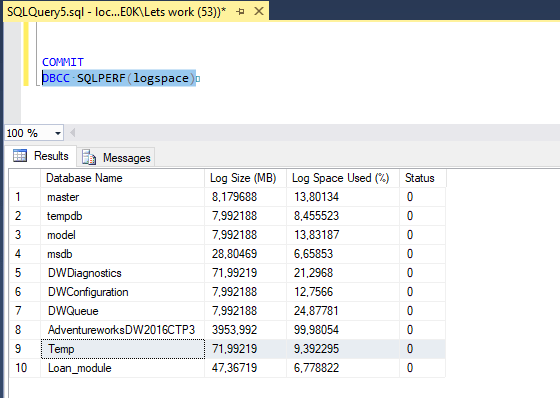
Transakce provede insert záznamů do tabulky [dbo].[Test_Transakcni_Log] a můžeme se podívat, jak nám to ovlivnilo transakční log. Pomocí Database console command DBCC SQLPERF(logspace) se můžeme podívat, že velikost logovacího souboru vzrostla na 72 MB z čehož je 43 % využito. 72 MB proto, že increment je nastaven na 64MB viz obrázek výše. Co se stane když nad transakcí spustíme COMMIT/ROLLBACK?
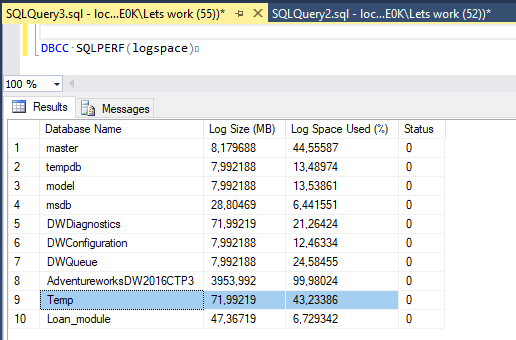
Potvrzení transakce příkazem COMMIT
Po COMMIT transakce znovu pouštím DBCC SQLPERF(logspace) a je vidět, že se transakční log téměř vyčistil. V případě, že bychom měli recovery model nastaven jako FULL, tak by data v logu zůstala až do doby, kdy je provedena záloha transakčního logu nebo jsme data z logu nevymazali.