

V předchozím článku SSIS | Úvod, BIDS, Project, Package, SSIS Toolbox jsem stručně představil featuru SQL Server Integration Services (SSIS) pro SQL Server. Cílem článku bylo usnadnit začátečníkům seznámení s pracovním prostředím, ve kterém můžeme vyvíjet datové integrace (ETL). Dnes se podíváme na control flow.
Shrnutí minulého článku o úvodu do SSIS
Víme, že datové integrace vyvíjíme v nástroji zvaném BIDS – Business Intelligence Development Studio (či nově SQL Server Data Tools), který má grafický interface a k vývoji nepotřebujeme umět programovat (ale pokud chceme můžeme programovat třeba v C#).
Základním prvkem SSIS je package (.dtsx) a jednotlivé packages sjednotíme v jednom nebo více projektech pro lepší přehlednost. Každý package má 1 nebo více connection managers, které definují připojení ke zdroji dat nebo cílové destinaci. Každý package může mít definovány své proměnné => variables.
V packages máme po levé straně tzv SSIS Toolbox, který obsahuje řadu komponent pro vývoj ETL procesů, které přetažením myši můžeme umístit do oblasti Control flow. Každá komponenta má určitý úkol – třeba logování nebo datové toky.
Pokud jste minulý článek nečetli, tak doufám, že vám krátké shrnutí pomohlo. Dnes bude řeč o Control Flow, kterým definujeme jednotlivé kroky SSIS package a pořadí jejich zpracování.
Control Flow v SSIS – Definice, Tasks, Containers a Data Flow
Control flow je základním stavebním kamenem každého SSIS package. Definuje totiž, co daná integrace provádí:
- Seznam operací (např Data flow task, Execute SQL task, Containers)
- Pořadí operací a vztahy mezi nimi (Precedence constrainst)
Oblast najdeme uprostřed pracovního prostředí. Automaticky ji vytvoříme po založení nového package (viz screenshot).
Do této oblasti můžeme z SSIS Toolboxu umístit různé prvky. Tyto prvky bych rozdělil do několika kategorií dle frekvence používání. Moje kategorizace se maličko liší od např Microsoftu, ale klasifikace podle řekněme důležitosti mi příjde přehlednější pro začátečníky:
- Data Flow Task (99 %) – Je pilířem datových integrací. Pomocí tohoto tasku se napojíme přes connection manager na zdrojová data, provedeme transformace a nahrajeme výsledek do cílové destinace. Pojmy Data Flow Task a Control Flow se často zaměňují, ale jedná se o 2 různé věci. Pokud si přetáhneme do Control Flow nový Data Flow task a otevřeme jej, tak v oblasti SSIS Toolboxu na nás čeká úplně jiná nabídka komponent, které nám pomohou dostat data z bodu A do bodu B.
- Execute SQL Task (80 %) – Tento task je také velmi frekventovaný a umožnuje v rámci běhu SSIS package pustit libovolný SQL script. Je vhodný například při logování průběhu, ale využití se dá najít mnoho.
- Containers (20 %) – Kontejnery slouží jako logická skupina tasků. Hlavní funkce jsou typicky 2
- Loop (For each loop container) – pro příklad pokud chceme loopovat nad nějakým adresářem, ve kterém se nachází více souborů, které chceme postupně zpracovat (fo each loop container)
- Sekvenční zpracování více tasků (Sequence container) – časté použití je poud máme několik data flow tasků, které nechceme zpracovávat postupně, ale paralelně (současně). Sekvenční kontejner nám umožňuje tyto data flow tasky seskupit. Pokud pak několik tasku zpracováváme v rámci kontejneru paralelně, tak SSIS package čeká až doběhnou všechny tyto tasky, následně prohlásí kontejner za dokončený a přikročí ke zpracování následující komponenty za kontejnerem
- Other Tasks (<5 %) – obsahují spoustu tasků, často administračního charaketru. Řada těchto tasků se dá alternativně řešit SQL scriptem (Execute SQL Taskem)
Shrnutí teorie Control flow v SSIS
Můžeme sem umístit celou řadu prvků, ale většina z nich je málo používaná
Ve většině případů v každém control flow figuruje Data Flow task (s ním si vystačíme) nebo Execute SQL Task. Tyto dva tasky jsou pro začátečníky naprosto OK a nic víc používat nemusíme. Alespoň ze začátku nám to vystačí na dlouhou dobu.
Pokud chceme zpracování SSIS package urychlit a máme tasky, které mohou probíhat nezávisle paralelně, tak tasky obalíme Sequence containerem.
Other tasks se používají naprosto minimálně a jsou spíše doplňkové.
Pro ilustraci: příklad Control flow by mohl vypadat například takto
- na začátu a na konci máme Execute SQL task (logování) a
- mezi logováním máme Data Flow task, který by provedl nějaký přesun dat

Pokud package pustíme tak jak jsem jej vytvořil na screenshotu, tak uvidíme situaci, která se nám moc nelíbí (viz screenshot dole). Proč? Protože v čase kdy jsem udělal screenshot ještě nemám zalogován Start a ETL část je již dávno hotová. Navíc se současně loguje i Konec SSIS.
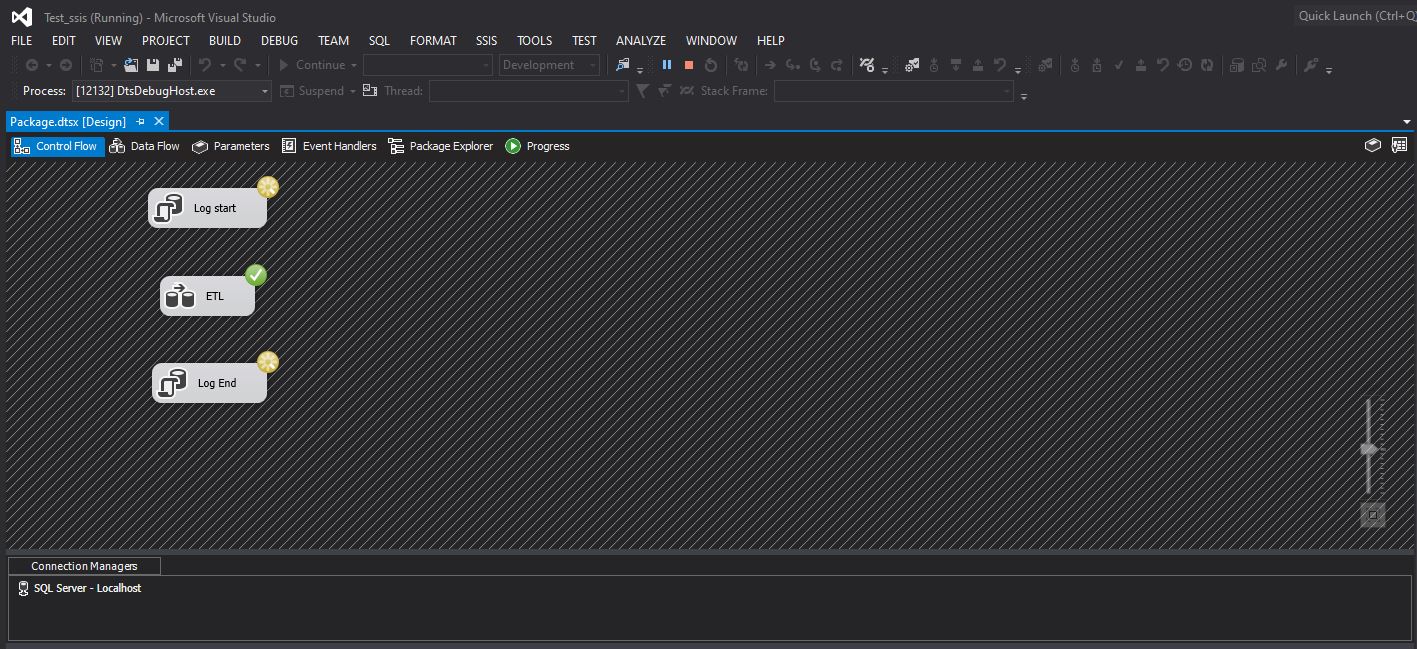
Precedence Constraints v SSIS – Řízení pořadí zpracování SSIS komponent
Takové chování není námi požadovaný stav a potřebujeme, aby se jednotlivé tasky pustili postupně na sebou. Jinými slovy potřebujeme nějak řídit pořadí zpracovávání. A přesně k tomu slouží precedence constraints.
Precedence constraints určují pořadí zpracovávání jednotlivých komponent.
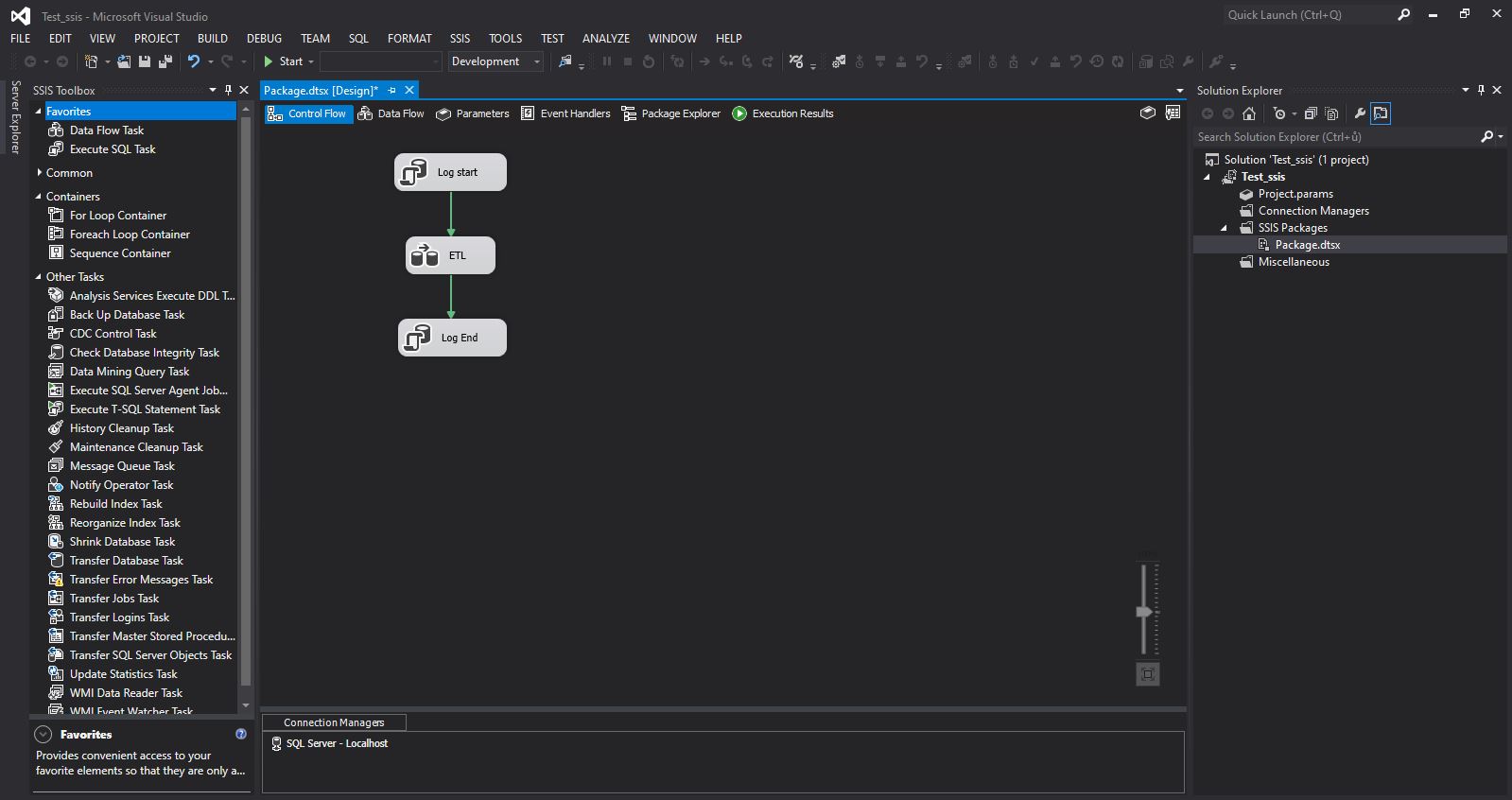
Za každou SSIS komponentou se nachází zelená šipka a připojením k jiné komponentě. Tím vyjádříme závislost. Říkáme tí, že komponenta od které vede šipka má být spuštěna jako první, poté co je úspěšně dokončena má být spuštěna další komponenta…a tak dále až k poslední komponentě (jako na obrázku).
Typy precedence constraints – defaultně jsou šipky zelené a to znamená, že další task je spuštěn po úspěšném dokončení předchozího tasku. Typů constraints je ale více
- Success (zelená) – následná komponenta bude spuštěna po úspěšném dokončení předchozí komponenty
- Failure (červená) – následná komponenta bude spuštěna po neúspěšném dokončení předchozí komponenty
- Completion (černá) – pokračování bez ohledu na výsledek
Závěr: Doufám, že se mi podařilo seznámit vás s Control flow. Na příkladech ve screenshotech máme vytvořen základ SSIS package. Chybí nám ale důležitá část – máme v Control flow sice vytvořenou základní strukturu package včetně Data flow tasku, ale zatím se v tomto tasku nenachází žádná ETL logika (zdroj a cíl dat, transformace). Na to se podíváme příště.