

Before introducing Control Flow, let me recap the previous tutorial SSIS | Introduction, BIDS, Project, Package, SSIS Toolbox where I introduced the SQL Server Integration Services (SSIS) feature for SQL Server. My goal was to show beginners a working environment in which we can develop strong data integrations (ETL).
Summary of the previous article – important terms are highlighted in bold
Data integrations are developed in a tool called BIDS – Business Intelligence Development Studio (or SQL Server Data Tools), which contain a graphical interface and development is without programming (but if we want, we can code in C#).
The basic element is the SSIS package (.dtsx) and individual packages can be unified into one or more projects for better clarity. Each package has 1 or more connection managers that define the connection to data source and destination. Each package has defined its variables.
In the workspace (BIDS) we have the SSIS Toolbox on the left, which contains a number of components for developing ETL processes that can be dragged and dropped into the Control flow area. Each component contains a certain logic – such as logging or data flows.
If you haven’t read the previous article, I hope that a brief summary has helped you. Today I will write about Control Flow, which defines individual components (steps) of each SSIS package and the order of their processing.
Control Flow in SSIS – Definition
Control flow is a significant cornerstone of each SSIS package and defines how the integration works. In general, control flow includes:
- Operations (eg Data flow task, Execute SQL task, Containers)
- Order of operations and relationships between them (Precedence constraints)
The control flow space is located in the middle of the workspace, which is automatically created when a new package is created (see screenshot).
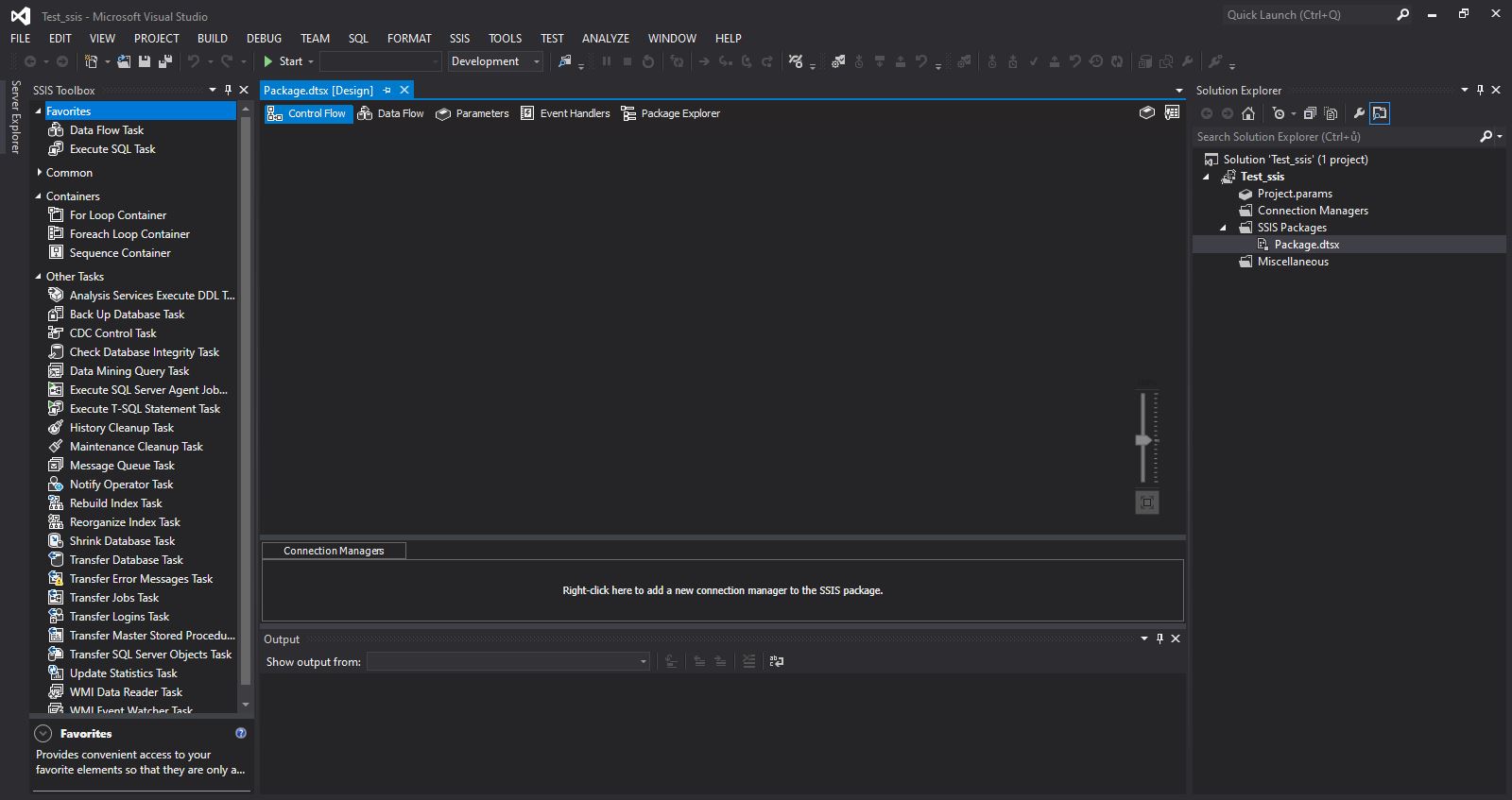
Control Flow – Tasks, Containers and Data Flow
Various elements can be placed into this area from the SSIS Toolbox. I would classify these elements into several categories according to the frequency of use. My categorization is slightly different from eg Microsoft, but the classification according to importance is in my opinion clearer for beginners:
- Data Flow Task (99%) – It is the pillar of data integration. Using this task we connect through the connection manager to the source data, perform transformations and load the result to the destination. The terms Data Flow Task and Control Flow are often confused. If we drag a new Data Flow task into Control Flow and open it, there is a completely different offer of components in the SSIS Toolbox area that will help us get data from point A to point B.
- Execute SQL Task (80%) – This task is also very frequent and allows us to run any SQL script within the SSIS package. It is suitable, for example, for logging, but there are many different uses.
- Containers (20%) – Containers serve as a logical group of tasks. The main functions are typically 2
- Loop (For each loop container) – for example, if we want to loop over a directory containing multiple files that we want to process (for each loop container)
- Sequence container – frequent use is only if we have several data flow tasks that we want to process in parallel (simultaneously). A sequential container allows us to group these data flow tasks. If several tasks are processed in parallel within the container, then the SSIS package waits until all these tasks have successfully finished. The following components are then processed after the container.
- Other Tasks (<5%) – include a lot of administration tasks. Many of these tasks can be alternatively executed using SQL script (Execute SQL Tasks)
(!) Control flow summary: We can put many components here, but most of them are rarely used
In most cases (especially for beginners) in each control flow there is a Data Flow task or Execute SQL Task.
If we want to speed up the processing of the SSIS package and we have tasks that can run independently in parallel, we put the tasks in the Sequence container.
Other tasks are rarely used
An example of Control flow (see below):
- at the beginning and at the end we have Execute SQL task (logging) and
- between logging, we have a Data Flow task that performs some data transfer

If we execute the package as it is in the screenshot, we will face a situation that we do not like (see screenshot below). Why? Because at the time the screenshot was created, we do not have a Start log even though the ETL part is already finished. All tasks start at the same time
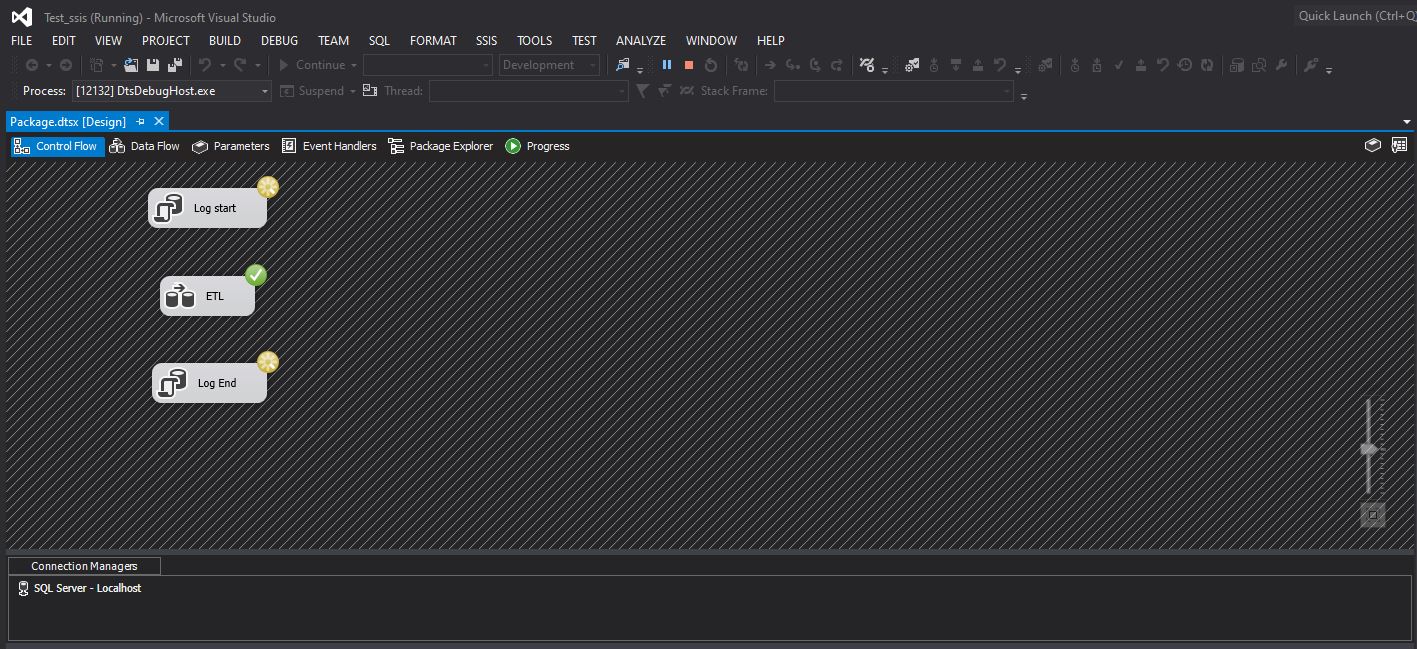
Precedence Constraints in SSIS and Classification – Control a processing order of SSIS components
Such behavior is not correct, and we need individual tasks to be launched one after another. In other words, we need somehow to control the processing order. And this is precedence constraints => determine the processing order of each component
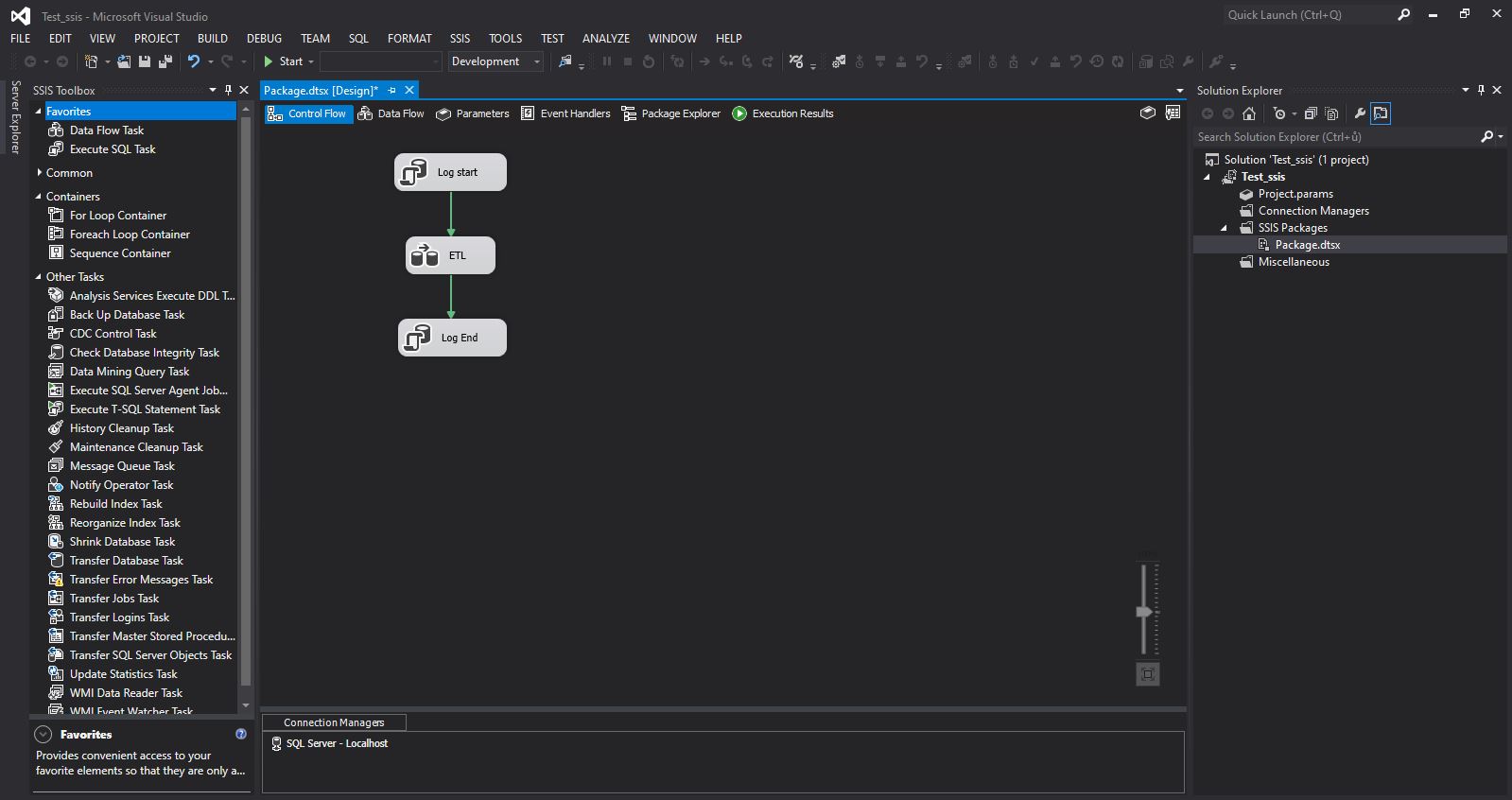
Behind each SSIS component is a green arrow with a connection to another component. This controls the dependency between components. We say that the component from which the arrow leads should be started first, and after it is successfully completed, the next component should be started … and so on to the last component (as shown).
Types of precedence constraints – by default, the arrows are green and this means that the next task is started after the previous task has been successfully completed. But there are more types of constraints.
- Success (green) – the next component will run after the previous component succeed
- Failure (red) – the next component will run after the previous component fails
- Completion (black) – continues regardless of the result
Conclusion: I hope that I was able to introduce you to the control flow. In the examples (screenshots) we have created a basic SSIS package. However, we miss an important part of the package. We created a basic package structure in Control flow including Data flow, but so far there is no ETL logic (data source and target, transformation). I’ll write about that next time
Log Start and Log End SQLStatement codes of these SQLStatement codes should be how the parameters resultsets should be, I wonder if you can give a detailed explanation 🙂
Log Start and Log End SQLStatement codes of these SQLStatement codes should be how the parameters resultsets should be, I wonder if you can give a detailed explanation.