

Většinou v Excelu pracujeme zejména s čísly (agregace přes SUMA, PRŮMĚR, apod) nebo s datumy a časem. Velmi často ale také potřebujeme upravovat, slučovat nebo čistit i sloupce s textem. Toho dosáhneme přes textové funkce, kterých je v Excelu spousta. Dokumentaci Microsoft k textovým funkcím v odkaze.
Situací kdy musíme text nějakým způsobem upravit je opravdu mnoho a nedá se to úplně zobecnit. Záleží případ od případu, ale ukázky použití viz níže pomůžou. Většinou tato potřeba nastává při exportu dat z nějakého podnikového systému, kde jsou určité hodnoty zadány nesrozumitelně nějakou hatmatilkou.
Excel nabízí zhruba 30 funkcí, které jsou přímo určeny pro práci s textem. Některé z nich se používají více či méně. V tomto článku najdete seznam těch nejpoužívanějších s příklady.
Pokud vás zajímá přehled nejpoužívanějších funkcí v Excelu a různé zajímavosti, tak si přečtěte článek Excel | Přehled nejčastějších otázek a odpovědí o Excel funkcích
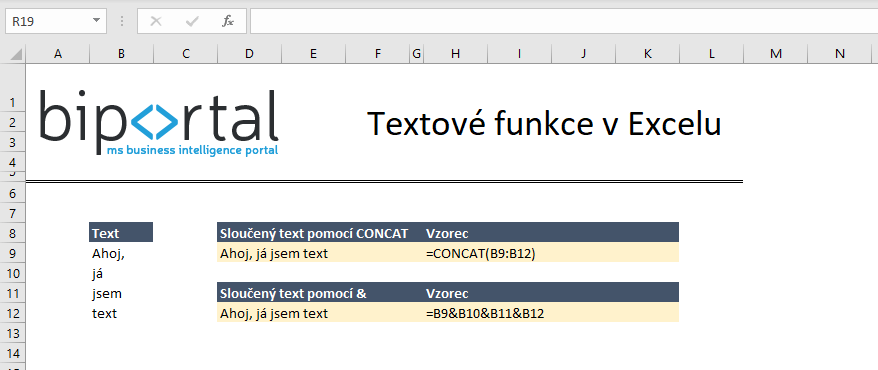
Sloučení textu, zřetězení textu – CONCAT(), TEXTJOIN() textové funkce nebo operátor &
Slučování textových polí je pravděpodobně nejčastější úlohou. Existují v zásadě 2 způsoby, jak můžeme sloučení textu provést:
- Pomocí funkce CONCAT() můžeme spojit více textů dohromady nebo
- Pomocí operátoru &
Syntaxe pro slučování řetězců
= CONCAT(oblast) nebo CONCAT (Buňka 1; Buňka 2; Buňka 3,…,Buňka n) – ve funkci odkazujeme na buňky
= CONCAT(“Text 1″;”Text 2”, “Text 3″,…,”Text n”) – pokud do funkce vepisujeme manuálně napsaný text, musíme jej dát do uvozovek
= Pro operátor & by byl zápis podobný, tedy =Buňka 1 & Buňka 2 & Buňka 3, …, Buňka n a alternativně pro text.
Tip: Zjevná výhoda CONCAT oproti & je fakt, že ve funkci můžeme odkázat na oblast a nemusíme tak jednotlivé buňky vyjmenovávat
Funkce TEXTJOIN umožňuje text slučovat efektivněji
V některých situacích je výhodnější používat funkci TEXTJOIN(). Ta provádí stejnou věc jako CONCAT, ale má jednu zásadní výhodu. U CONCAT nemůžeme zvolit vlastní oddělovač slov – v našem případě je oddělovačem mezi slovy mezera. V ukázce výše je tato mezera součástí jednotlivých slov v tabuce. Pokud by tomu tak nebylo, tak použijeme funkci TEXTJOIN, ve které můžeme oddělovač stanovit
Syntaxe: TEXTJOIN(<oddělovač>;<ignorovat prázdné buňky (true, false)>;<text>
O funkcích CONCAT a TEXTJOiN je zde na webu samostatný článek – CONCATENATE, TEXTJOIN | Excel – Slučování textových řetězců a buňek
Nahrazení hodnoty v textu – DOSADIT() nebo SUBSTITUTE() funkce
Další užitečná dovednost je umět nahradit pomocí vzorce určitou hodnotu v textu a dosadit místo ní hodnotu jinou. K tomu se používá funkce DOSADIT nebo alternativně v anglické verzi Excelu funkce SUBSTITUTE.
Syntaxe pro nahrazení textu
=DOSADIT(<buňka, ve které je text>; <hodnota, která se má nahradit>; <nová hodnota>)
Dejme tomu, že bychom chtěli změnit v předchozím příkladu Text “Ahoj” za “Dobrý den” a až poté všechny slova sloučit. Vypadalo by to jako na obrázku.

Zjištění délky textu (počet znaků) – Funkce DÉLKA() nebo LEN()
Počet znaků v textovém řetězci se dá změřit pomocí funkce DÉLKA() nebo LEN() v případě anglické verze. Funkce vrací délku textového řetězce z hlediska počtu znaků.
Například výraz DÉLKA (‘Ahoj’) by vrátil hodnotu 4. Pokud existují mezery na konci textu, tak je funkce do celkového počtu znaků započítá také.
Syntaxe pro změření délky textu
=DÉLKA(<buňka ve které je text>)

Poznámka: Funkce v tomto případě vrací o 1 znak navíc, protože v textu jsou mezery.
Extrakce části textu – Textové funkce ZLEVA(), ZPRAVA(), ČÁST() nebo LEFT(), RIGHT(), MID()
Další situace, do které se můžeme někdy dostat je ta, že potřebujeme z textu vybrat libovolný počet znaků buď zleva, zprava nebo někde uvnitř textu.
Syntaxe pro počet znaků zleva
=ZLEVA(<buňka ve které je text>;<počet znaků, které chceme vybrat>)
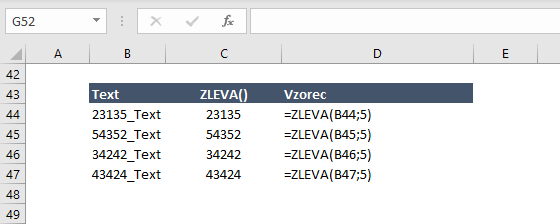
Poznámka: Pokud se část textu, který potřebujeme získat nachází někde uvnitř jiného textu, tak volíme funkci ČÁST()
Pročistit mezery v textu – Funkce PROČISTIT() nebo CLEAN()
Někdy máme k dispozici textové hodnoty, které obsahují např. na začátku, na konci nebo mezi slovy mezery navíc. Pomocí funkce PROČISTIT můžeme tyto nadbytečné mezery vymazat. Tato funkce funguje tak, že z textu odstraní:
- Všechny mezery zleva (před textem)
- Všechny mezery zprava (za textem)
- Pokud text obsahuje více slov, tak ponechá 1 mezeru mezi slovy – ostatní mezery vymaže
Syntaxe pro zrušení mezer v textu
=PROČISTIT(<TEXT>)
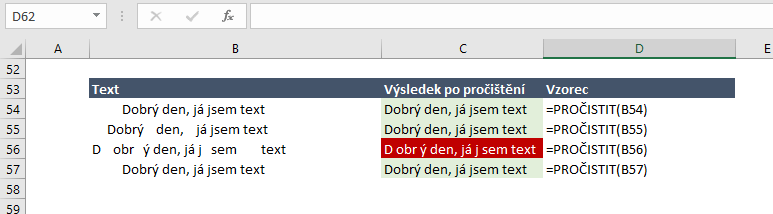
Na screenshotu vidíme text “Dobry den, já jsem text” s tím, že jsem do něj 4x různě vložil mezery. Pro pročištění většina variant dopadla dobře, ale 3. varianta je rozbitá. Funkce totiž chápe jednotlivé znaky oddělené 1 nebo více mezerami jako jednotlivá slova a nechá mezi nimi po pročištění 1 mezeru.