

Performance optimizing SQL queries is an ongoing battle that begins right from the design of the database architecture and server resource scaling. With the right architectural design, many performance issues in the future can be avoided. Additionally, script performance can be influenced by the structure of SQL queries and properly configured indexes. This article is divided into 2 main sections:
- How to Optimize Using SQL Architecture
- How to Optimize with the Structure of SQL Scripts
Performance optimizing Using Database and Server Architecture
Below, I will provide the biggest drivers from an architectural perspective that have an impact on query performance.
Database Model
The structure of tables and their cardinality relationships have a significant impact on the database’s usability in the future. Poorly structured databases with inappropriate relationships between tables can lead to future problems. Scripts will become more complex, containing many transformations that slow down query performance, and maintaining such a database will become costly over time.
When deciding on the database architecture, you must decide whether the structure should be optimized for writing (applications) or primarily for reading (e.g., data warehouses). For data warehouses, we choose structured models with fact and dimension tables in a star schema or snowflake schema – more common.
Choice of Data Types for Fields in Tables
It’s worth considering data types. If possible, use INT or BIGINT data types for primary keys because GUIDs are slower in script execution, and indexes for GUIDs are much larger than those for INT, for example. Data types (not only numeric ones) should be chosen to have the smallest size possible. You can find an example of the sizes of numeric data types in the article – Numeric Data Types – Overview. Optimization in this case is mainly ensured by efficient joining and faster DML operations.
Indexes
Indexes are fundamental. Creating primary keys for all tables is a must, as they are indexes themselves (clustered index). In addition to that, you need to optimize queries by creating non-clustered indexes. If you’re not sure how to do it, take a complex script that is frequently executed on the database and have it display the Estimated Execution Plan.
If the SQL Engine sees room for optimization in your query, you will see a green notification for Missing Index + the percentage impact on query acceleration if you decide to create the index. You can generate a script to create an index by right-clicking and selecting “Missing index details.” In the case below, the execution plan recommends creating a non-clustered index and promises an expected 8% reduction in query overhead. Often, you can speed up more complex queries (multiple joins + WHERE criteria) in this way by up to 90%.
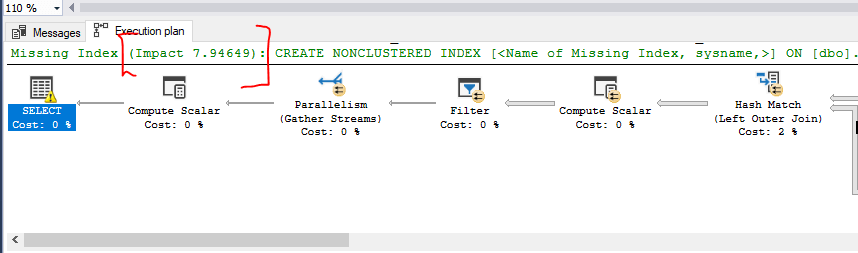
Generally, it’s better to use more slender indexes (with fewer fields) rather than a few thick indexes. The effectiveness of indexing decreases with the number of fields included in the index. I have written a few articles about indexes, which you can find in the list below:
- Indexing Theory
- Index Fragmentation – Examples + Scripts
- Automatic Index Maintenance + Script (will be translated)
Partitioning (Partitioned Tables)
This can often be a lifesaver. Partitioning is used for very large tables. As an example, I will mention a table that logs accesses (or an equivalent). If you have a similar table that contains older data that is not queried as often, consider this optimization method. It involves physically dividing the table (via filegroups) into several parts (partitions) – SQL Server supports this, and the whole process can be done relatively easily using partition functions, where you define the criterion for separating data.
Newer data that is queried more frequently can also be placed on a faster disk, and older data on a slower one, for example, using new technology available since SQL Server 2016 called Hybrid Cloud (Stretch Database). Both partitions can be left on the same disk in different filegroups, and this has a significant performance effect – you only query one filegroup that contains far fewer records.
I realize that I don’t have any articles on partitioning on my blog, so I need to fix that.
Scaling and Server Connectivity
There is always room for performance optimization that does not involve hardware scaling. However, if you feel that there is little room left for optimization, and it is not effective to dedicate yourself to such optimization, consult with your server administrator. Perhaps together you will come to the conclusion that it makes sense to allocate additional resources to your virtual server (processors, RAM, disk space for indexes).
Performance optimizing of SQL Queries
Below, I provide a few examples and recommendations for optimization. However, in general, before running a script, read it twice and consider whether it can be simplified and improved with a focus on SQL query performance. This is even more true for frequently used scripts. For those, go through the script four times and create indexes for it :). Let’s get started…
Query Specific Columns in the Table
Use specific columns in the table you are about to use instead of SELECT *. If you are running a query just to get an overview of the table (e.g., you need to see a list of columns), use the TOP clause – for example:
SELECT TOP 10 <columns>
FROM <Table>
Minimize the Use of Functions in the WHERE Clause and Especially in the FROM Clause
Considering the Logical Processing of SQL Queries, it is advisable not to use too many functions in the WHERE or FROM clauses. The FROM clause logically processes the query as the 1st clause, and the WHERE clause as the 2nd. As a result, functions are applied to all records in the table, which does not benefit performance. An index on the field in the condition is also not utilized, resulting in a full table scan.
Don’t Join Tables Using a Cartesian Product, Use INNER JOIN
Do not use joins in this format:
SELECT <Column_1>, <Column_2>
FROM <Table_1>, <Table_2>
WHERE <Table_1>.ID = <Table_2>.ID
The query is processed in such a way that a Cartesian product is first created using CROSS JOIN (FROM is processed as the 1st clause), and then the data is limited in the WHERE clause (processed as the 2nd). If a table has 100,000 records, using a Cartesian product creates 100,000 * 100,000 records, and then the data is limited, which is inefficient, and query optimization is needed. Instead, use:
SELECT <Column_1>, <Column_2>
FROM <Table_1> INNER JOIN <Table_2>
ON <Table_1>.ID = <Table_2>.ID
Efficiently Use Wildcards and the LIKE Operator
Searching through string values is one of the most performance-intensive operations. An inefficient query on a table using LIKE with wildcards might look like this:
SELECT <Column_1>, <Column_2_String>
FROM <Table_1>
WHERE <Column_2_String> LIKE ('%ABC%')
This is inefficient because the wildcard % is used on both sides of the string being searched. Before using a wildcard, consider whether you can come up with a better pattern, for example:
SELECT <Column 1>
FROM dbo.Table
WHERE <Column1> LIKE '__ABC%'
The second query will be much more efficient in terms of optimization because we specify that the string ABC is located at positions 3-5 from the left, so we are only searching the right part. You can learn how to use wildcards in more detail here – LIKE Operator.
Minimize ORDER BY If It’s Not Necessary
ORDER BY is a very expensive operation, and if it’s not necessary, avoid using it unnecessarily.