

Minule jsme udělali takový větší deep dive do toho jak funguje Keboola storage, jak aplikace zpracovává a jak ukládá data během nějakého flow. Dneska ukážu, jak fungují v Keboole transformace. Vytvoříme si mnohem komplexnější Flow, které napočítá data ze zdroje a poté aktualizuje Power BI report.
Keboola Transformace (ETL přístup) – kdy je používat
Transformace jsou v Keboola hlavním stavebním kamenem ETL přístupu (extract, transfer, load). Pro zopakování:
- ETL koncept zpracování dat: provedete na úrovni zpracování dávky nejprve extrakci ze zdrojového systému, následně data zpracujete a ztransformujete (do datasetů, sémantického modelu atp) a nakonec data nahrajete do cílového úložiště.
- ELT koncept – Protikladným přístupem je ELT kdy nástroj používáme pouze pro Extrakci a load s tím, že transformace probíhá až potom. To má výhodu v tom, že transformaci můžeme provádět jiným nástrojem (například dbt nebo databázové procedury) a způsobem, který nám vyhovuje.
Keboolu můžeme používat samozřejmě jako ELT nástroj (transformace můžeme vynechat). To je u Kebooly výhoda. Transformace najdeme v Menu pod položkou “Transformations”.

Jaký máme Data engineering úkol pro tento článek?
Přemýšlel jsem a co třeba toto: Úkol: Vytvořit data Flow, které se skládá z následujících kroků:
- Natáhnout data z AdventureWorks
- Uložit surová data do Keboola úložiště
- Následně provést denormalizaci kde výsledkem bude dataset pro reporting (transformace)
- Tento dataset uložíme do naší Snowflake instance
- Nakonec aktualizujeme Power BI report, který je napojen na dataset z předchozího kroku
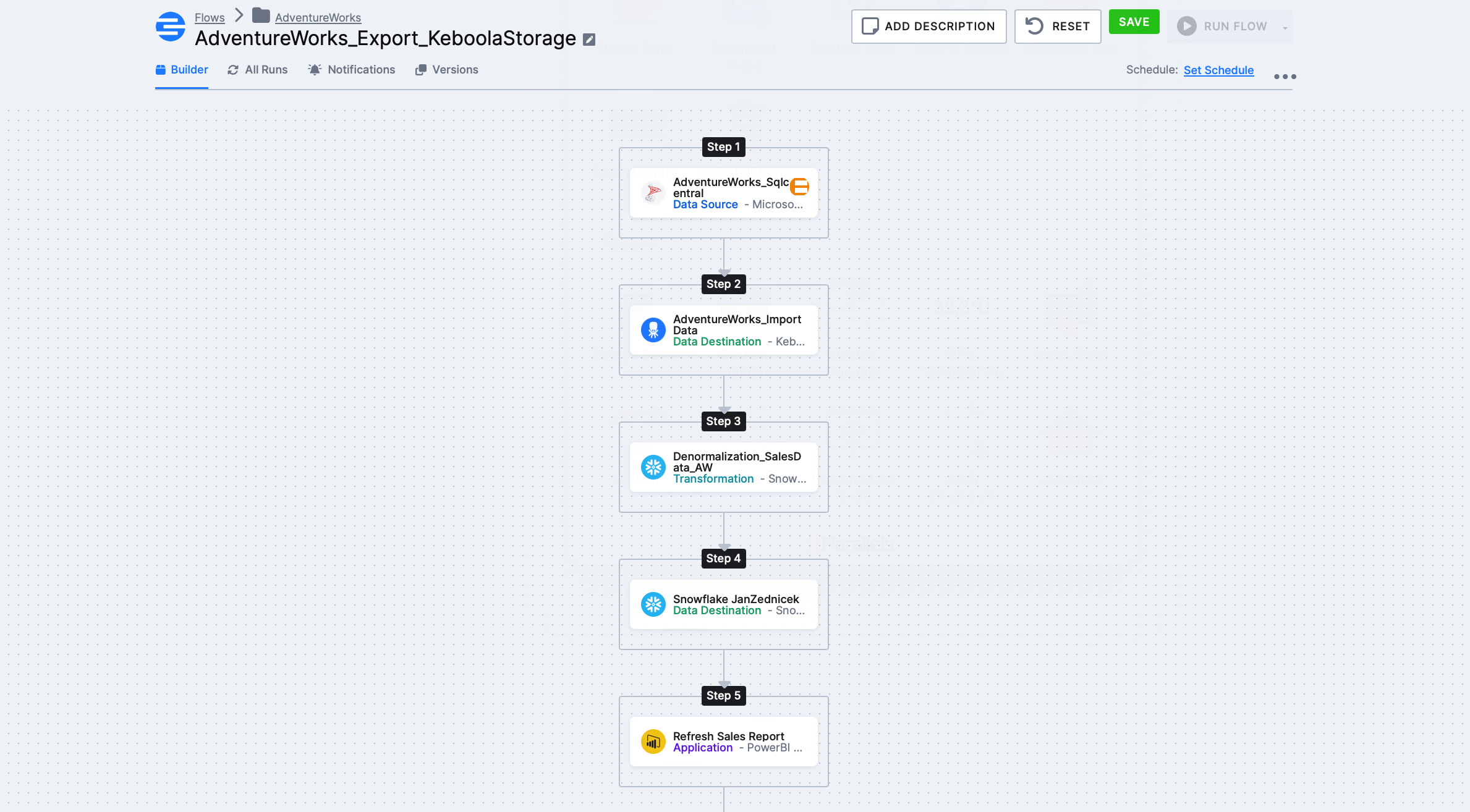
Ve finále potřebujeme dostat toto flow s tím, že krok Step 3 – Denormalization_SalesData_AW je pro nás naše transformace o které tu budu hlavně psát. Ostatní komponenty (source, destination) jsem už prošel dříve ve článku s Flow.
Typy Transformací v Keboole
Transformace fungují jako komponenta ve flow. Typicky tato transformační komponenta následuje po extrakci ze zdrojových systémů a přijímá jako vstup nějaká data z Keboola storage (IN bucket). Tato data si tedy převezmete do transformační komponenty a můžete s nimi něco provést
Nástroje a možnosti pro provedení transformace
- Python transformace
- R transformace
- Snowflake transformace
- No-code transformace
- dbt core transformace
Způsob provedení transformace závisí na vašich znalostech, architektuře řešení a preferencích

Transformační skripty dle volby si můžeme připravit v tzv. Workspaces.

To jsou pracovní prostory, které si vytvoříte v Keboola aplikaci a je to velmi užitečná featura z mnoha důvodů. Z pohledu transformací je pracovní postup zhruba následující:
- Chci udělat transformaci a potřebuji si někde odladit skript
- Založím si snowflake workspace
- Následně je nakrmíte datama (naklikáte tabulky z Keboola storage, které se mají do tohoto prostoru nahrát)
- Vytvoříte skript a tento skript použijete v transformační komponentě
Jak vytvořit Keboola Snowflake transformaci?
Dříve než začnu psát pracovní postup, tak se podíváme na to, jak vypadají naše zdrojová data. V rámci naší “AdventureWorks_sqlcentral” source komponenty (viz screenshot výše – step 1) a následné “DataAdventureworks_importdata” se nám stáhnou data, která se po extrakční části uloží do Keboola storage.
Cílem je tato data po nápočtu spojit do 1 datasetu prostřednictvím transformace tak, abychom je následně mohli nahrát do jednoduchého power bi reportu jako 1 tabulku (který rovnou aktualizujeme).

Krok 1 – Vytvoření transformace – Kliknu v menu na Transformace – create new transformation a vybereme Snowflake transformation

Krok 2 – naplnění transformace tabulkami – Dále je potřeba nastavit, které tabulky z Keboola backend (Snowflake) do transformace (a) vstupují -IN a (b) vystupují -OUT. To si naklikáme na další obrazovce. Poté, co naklikáme vstupní a výstupní tabulky potřebujeme dát nějak dohromady SQL skript pro danou transformaci. Nebudeme ho přece vymýšlet zpaměti. K tomu slouží volba vpravo – tabulky si mohu naimportovat do existujícího workspace nebo můžu založit nový snowflake workspace.
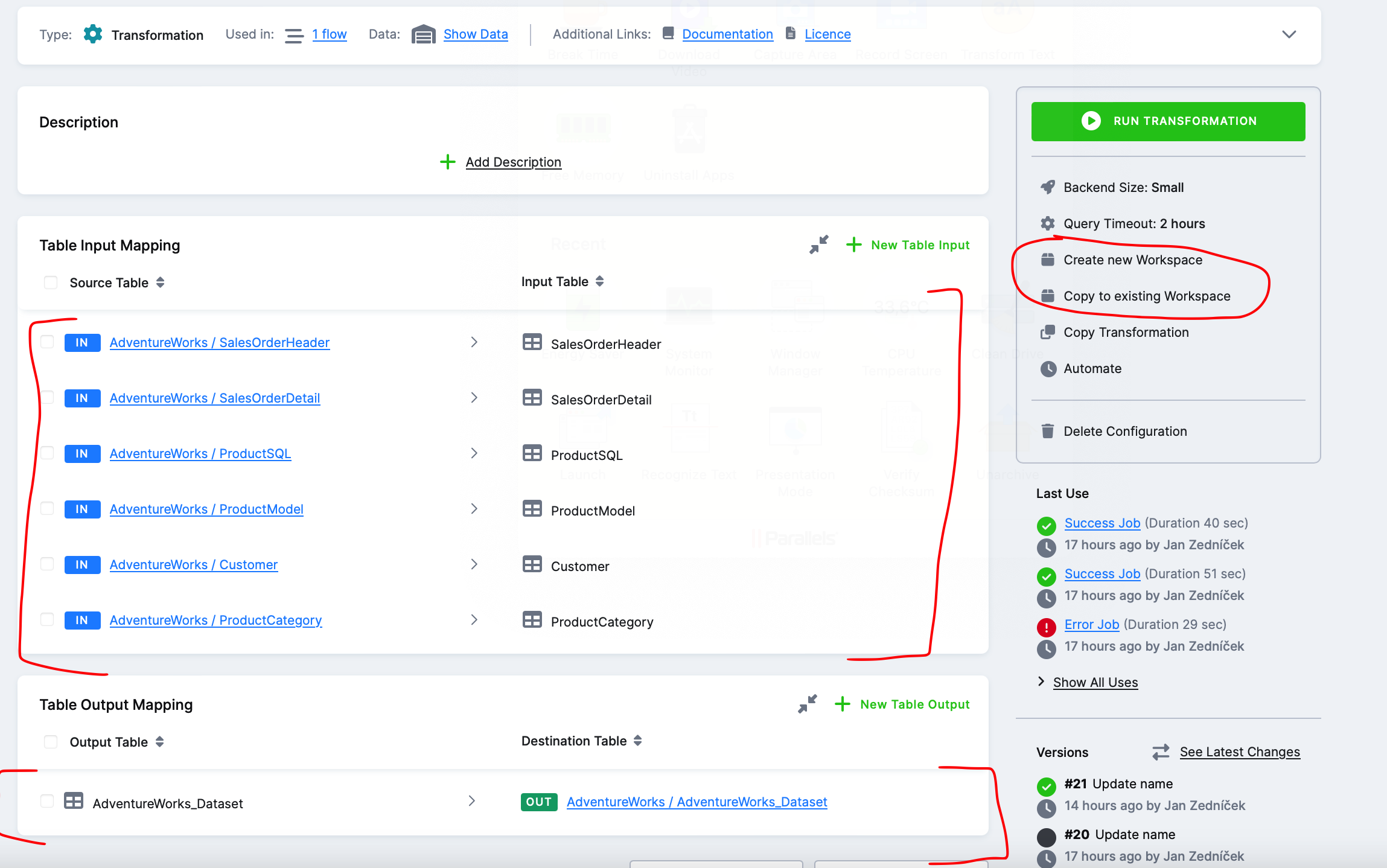
Krok 3 – Vytvoření Snowflake workspace – Vytvoříme si nový snowflake workspace kde si připravíme skripty

Krok 4 – přihlášení do Snowflake instance – chvíli počkáme než se nám vytvoří prostředí ve snowflaku a poté co je hotovo nám Keboola zobrazí přihlašovací údaje. To co se právě stalo je, že v Keboola Snowflake backendu se nám vytvořila databáze s našimi daty a uživatel, který má práva k této databázi.

Klikneme na host odkaz a přihlásíme se pomocí poskytnutích údajů. Na screenshotu níže vidíme, že je vše připraveno. Máme připravenou databázi s našimi tabulkami a můlžeme ladit skript

Krok 5 – Příprava skriptu pro transformaci – Otevřeme si ve Snowflake nový SQL worksheet a spojíme si tabulky do nějakého smysluplného datasetu.

Skript, který jsem použil je níže:
SELECT
“SalesOrderDetailID”
,”OrderQty”
,”UnitPrice”
,”UnitPriceDiscount”
,”LineTotal”
,”sh”.”AccountNumber”
,”cu”.”CompanyName”
,”cu”.”FirstName”
,”cu”.”LastName”
,”cu”.”EmailAddress”
,”sh”.”OrderDate”
,”pr”.”Name” AS “ProductName”
,”pm”.”Name” AS “ProductModel”
,”pc”.”Name” AS “ProductCategory”
FROM “SalesOrderDetail” “sd”
LEFT JOIN “SalesOrderHeader” “sh”
on “sd”.”SalesOrderID” = “sh”.”SalesOrderID”
LEFT JOIN “ProductSQL” “pr”
on “sd”.”ProductID” = “pr”.”ProductID”
LEFT JOIN “ProductModel” “pm”
on “pr”.”ProductModelID” = “pm”.”ProductModelID”
LEFT JOIN “ProductCategory” “pc”
on “pr”.”ProductCategoryID” = “pc”. “ProductCategoryID”
LEFT JOIN “Customer” “cu”
ON “sh”.”CustomerID” = “cu”.”CustomerID”;
Krok 6 – Dokončení transformační komponenty – Pokud jsme se skriptem už OK, tak se vrátíme do transformační komponenty. JEdiné co přidáme navíc je DDL CREATE TABLE AS. Transformace pak udělá během našeho Flow to, že si přečte data z tabulek, spojí je pomocí skriptu a následně výsledek uloží pomocí CREATE do Keboola storage. Díky tomu si pak můžeme na výsledek transformace sáhnout v další fázi našeho flow.

Krok 8 – Dokončení Flow – Poté co je hotová transformace můžeme pokračovat dalšími kroky v našem flow. Naplníme daty naši databázi a následně můžeme načíst nová data do našeho power bi reportu.
