

V minulém díle nazvaném ETL | Keboola Free (zdarma) – Vytvoření projektu, základy jsme dělali základní seznámení s aplikací. Prošel jsem postup při založení projektu a také jsme orientačně prošli strukturu Kebooly a menu. Dneska bych se chtěl ukázat, jak jednoduché je vytvořit Keboola flow. Flow je v Keboole označení pro pipeline, data flow, datový tok (jak chcete)
Keboola Flow – Úvod a úkol – data z SQL Server do Google drive
Flow se nachází v horní části menu pod položkou Flow (původně orchestrace ve starší verzi Kebooly).
Úkol – Za úkol máme importovat data ze zdroje do destinace přičemž
- Zdroj – databáze SQL Server AdventureWorks – zajímá nás tabulka “Customer”
- Cíl – cílová destinace je můj Google Drive – složka Keboola_GoogleAnalytics/janzednicek_flow
Přehled flow, které jsme vyrobili v tomto článku
- Celková doba – potřebná k nastavení tohoto flow je cca 10-15 minut
- Zdrojová tabulka – Customer (850 záznamů) na SQL Server
- Cílová tabulka – Customer na Google drive
- Celková doba běhu – 1 minuta
- Náklady – 0 CZK
Založení data flow source komponenty v Keboole, advanced mode
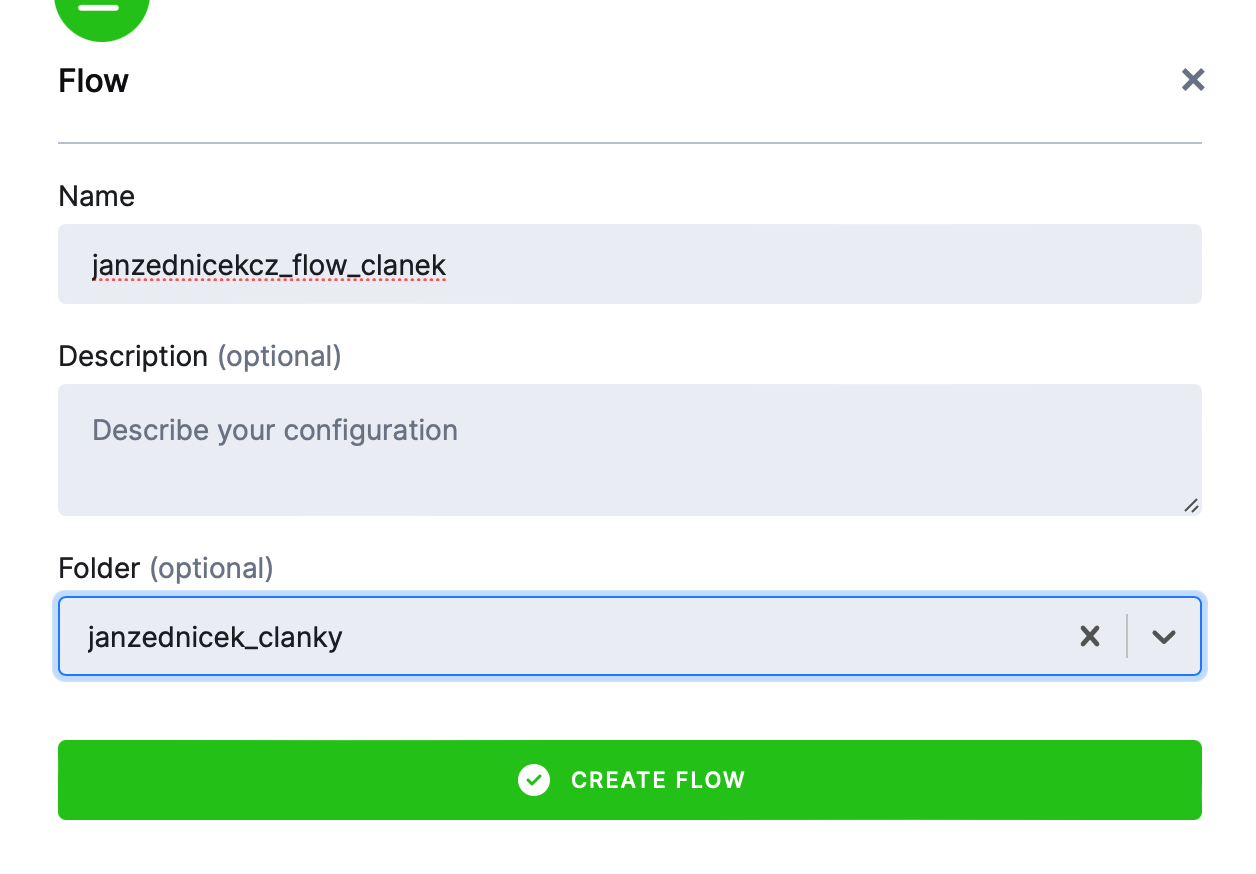
1) Založení flow – klikneme na create flow a zobrazí se nám okno, kde to po nás chce zadat název nového flow a případně složku, do které jej uložíme.
- název – janzednicekcz_flow_clanek
- složka – janzednicek_clanky (očekávám, že těch flow budu mít více)
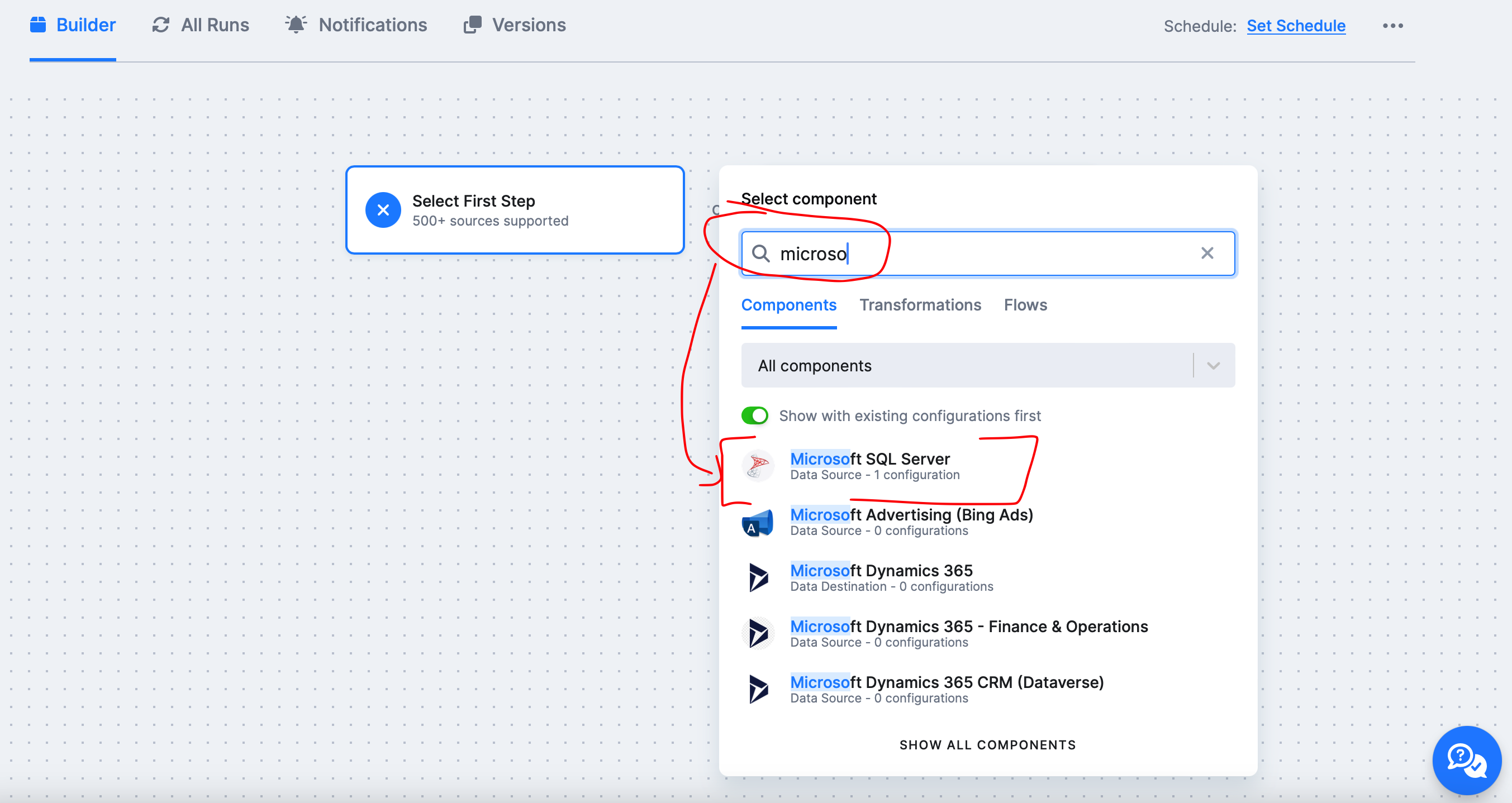
2) Prostředí Flow – Keboola nás vezme do prostředí námi založeného flow na této obrazovce máme na výběr
- Select First Step – což znamená, že si Flow vytvoříme od nuly
- Use Template – V Keboole je pár desítek templates (předpokládám že další budou přibývat), které můžete použít jako vzor
My vybereme SELECT FIRST STEP

3) Výběr komponenty Data source – Po kliknutí na “Select first step” je potřeba vybrat komponentu ke které se budeme připojovat. V našem případě Microsoft SQL Server Data source.
4) Klikneme na Create configuration a nazveme si naši konfiguraci. Nastavené kongigurace lze používat opakovaně takže se snažíme aby byly pojmenovány rozumně.

5) Vyplníme přihlašovací údaje a klikneme na test connection and load available sources.

7) V případě, že se Keboola podařilo přihlásit k datovému zdroji, tak automaticky načte všechny tabulky, které jsou k dispozici pod daným účtem.

8) Advanced mode – Můžeme ale chtít načíst data takto jednoduše, ale taky je můžeme chtít načíst prostřednictvím SQL scriptu protože je chceme upravit nebo něco vynechat. V tom případě klikneme na advanced mode.
Zde si můžeme nadefinovat spoustu dodatečných nastavení nad jednotlivými tabulkami, případně si můžeme vytvořit nový objekt a vložit skirpt. Podívejme se na nastavení u tabulky customer, kterou máme za úkol stáhnout. Na advanced mode udělám později separátní článek.
V advanced modu můžeme nastavit např:
- Výběr sloupců
- Název a nastavení uložení na Keboola storage
- ! Incremental fetching
- CDC – pokud je zapnuto na zdroji
- Na základě sloupce (např. modified)
- Nastavení primárního klíče, nolock option
- Write query option


9) Výběr tabulky – Zůstaneme v advanced modu, vrátíme se o krok zpět na výpis tabulek a necháme v seznamu pouze tabulku Customer, zbytek vymažeme.

Nastavení Keboola komponenty Destination – Google drive
10) Google drive destination – Vrátíme se do Flow a vybereme další komponentu – Google drive

11) Autorizace – Nastavení autorizace (přístupová práva) komponenty můžeme udělat
- Online (instant) autorizaci, kdy vás Keboola autorizuje pomocí google účtu
- External autorization – prostřednictvím odkazu
- Custom autorization (oAuth2 – nejbezpečnější) – client + secret
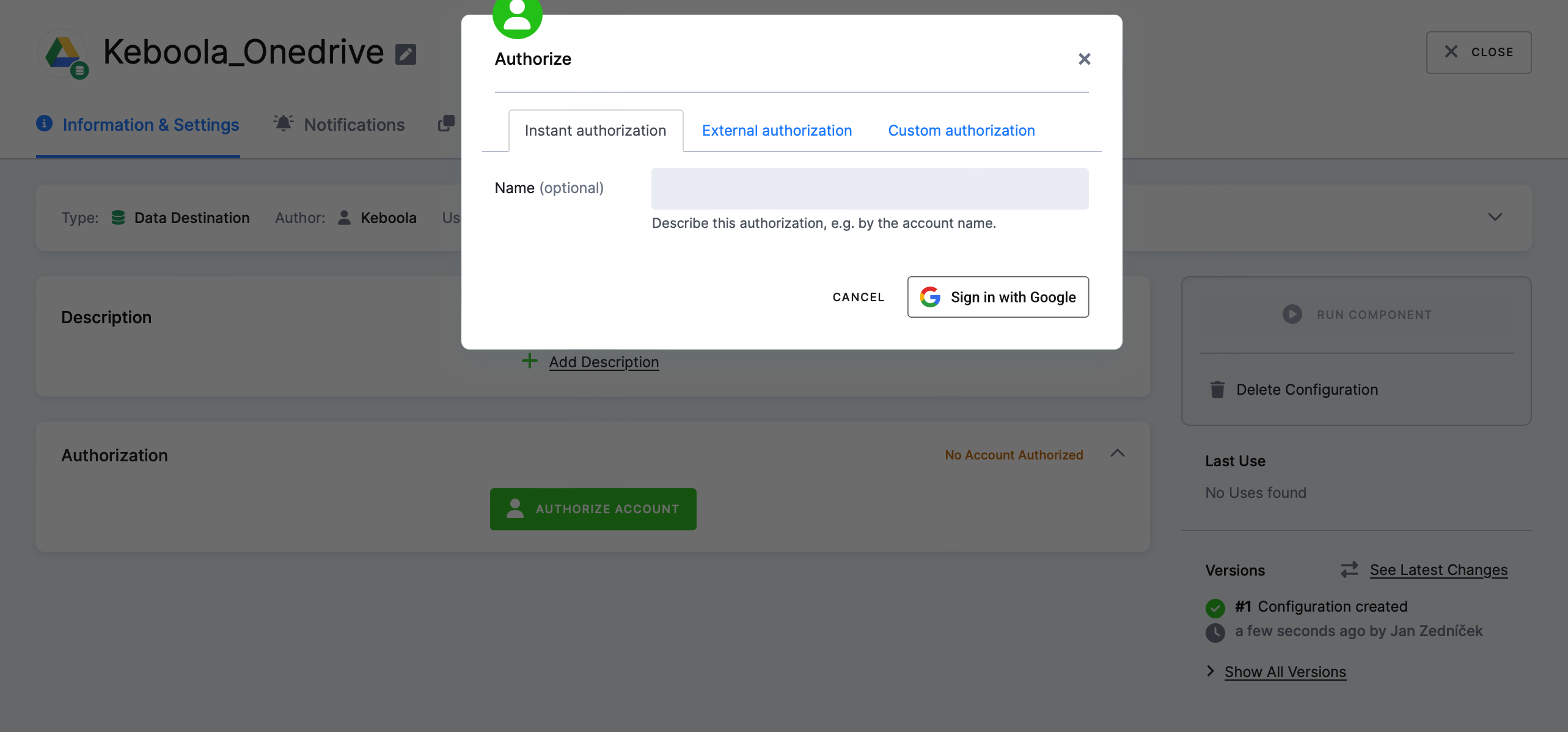
12) Výběr source table – po úspěšně autorizaci klikneme na Add table. Následně se nás Keboola zeptá, jestli chceme cílovou tabulku updatovat nebo vytvořit vždy tabulku novou (full load). Vybereme třeba Create new table.

13) Google drive a výběr umístění – Posledním krokem je výběr složky na Google drive kam chceme naši tabulku prostřednictvím Kebooly nahrát.

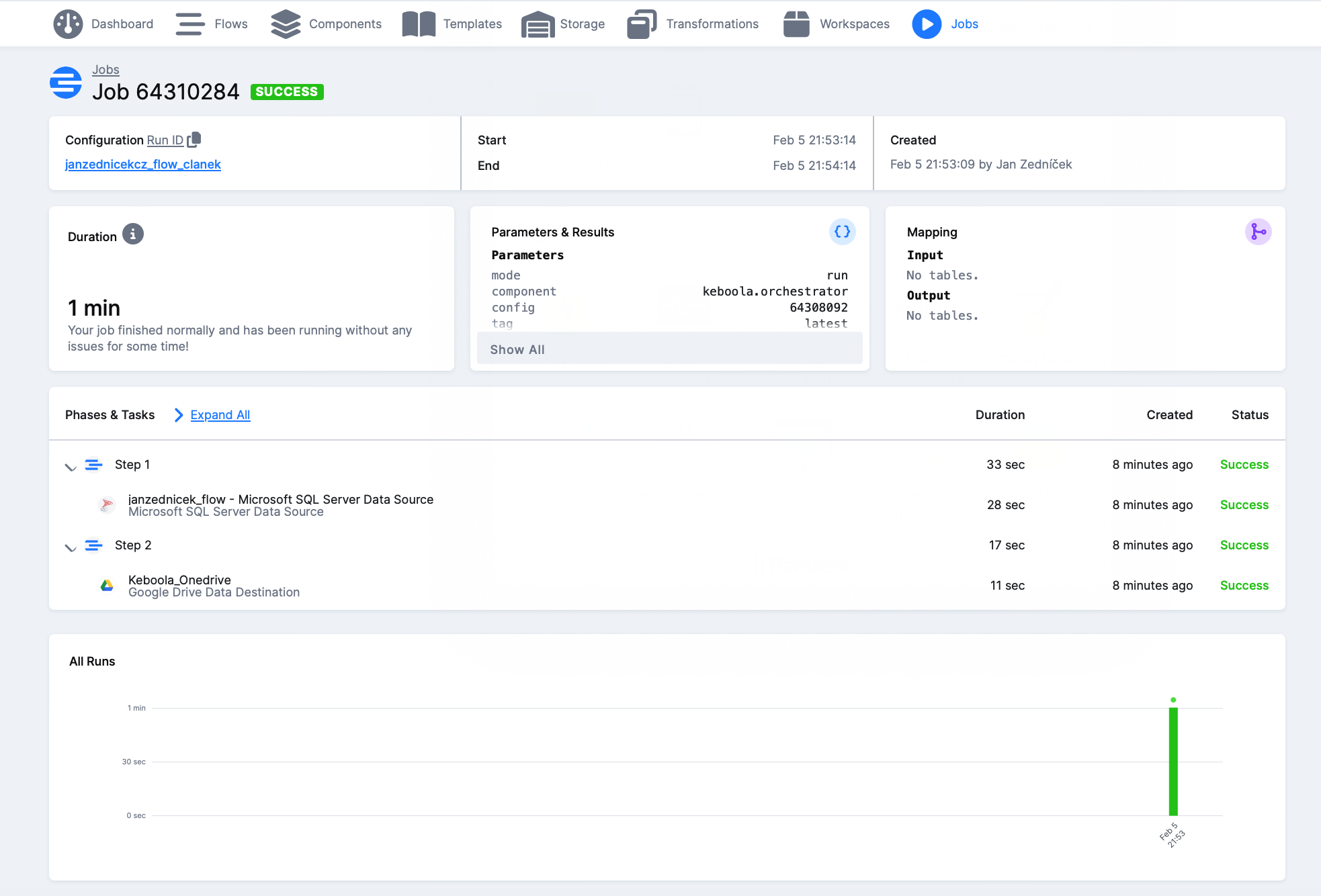
14) Spuštění hotového flow a kontrola
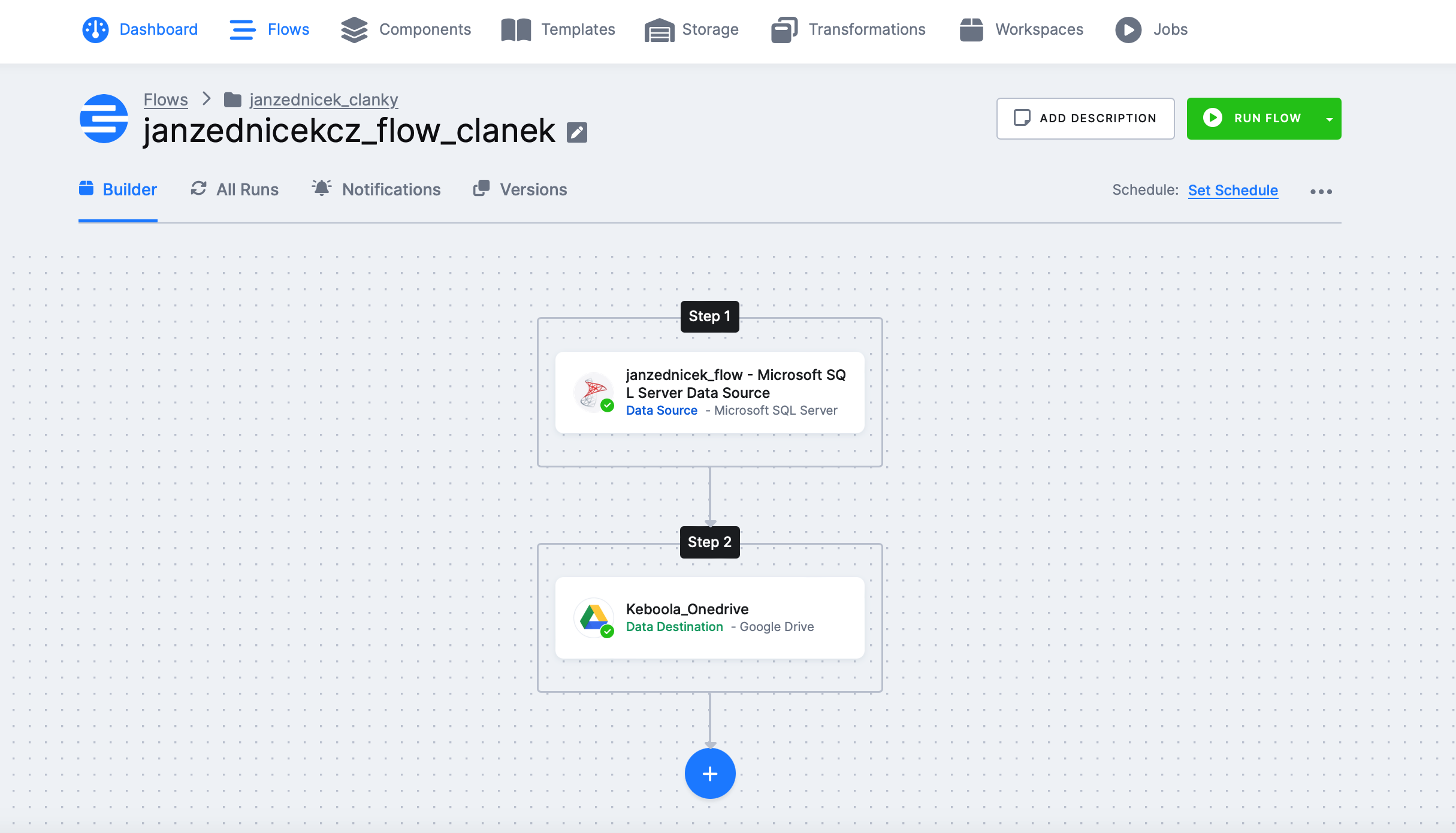
Keboola soubor Customer vyexportovala na můj google drive
