V předchozím článku jsme si udělali menší úvod- ETL | Keboola – Úvod, Pricing, Produkty – Alternativa Fivetran. Víme, že Keboola nabízí Freemium model, takže si můžeme tento nástroj vyzkoušet zdarma. Budeme muset pouze strpět limitace co se týče používání (limit počtu minut je 120). Podíváme se, jak vypadá prostředí v aplikaci a seznámíme se s demo projektem, což je určitá forma tutoriálu, kterým Keboola zaškoluje nové uživatele na reálných příkladech.
Keboola Free – jak vytvořit účet a projekt?
Keboola má dovovskou stránku – https://www.keboola.com. Nejprve se zaregistrujte pakliže ještě účet nemáte

Po registraci klikneme na Start Free Project a Keboola nás provede založením nového projektu. Před založení projektu dostaneme možnost dostat školení (pokud chceme) v podobě
- Demo projektu – demo projekt je možné proklikat bez nutnosti registrace
- Edukačního videa
- Můžete požádat o hovor se zástupcem Kebooly, který vám aplikaci předvede

Pokud nechceme, tak se se vrátíme o krok dozadu a necháme se přesměrovat rovnou do aplikace. Defaultní stránka po přihlášení je dashboard našeho projektu.

Struktura Kebooly – Menu, dashboard, komponenty, storage, jobs, aj.
Jak jsem již poznamenal, dashboard je defaultní page kam se dostaneme.
Dashboard – vše podstatné na jednom místě
Na dashboardu vidíme všechny základní charakteristiky našeho projektu zejména:
- Přehled storage (zabrané místo na Keboola disku) – kapacita k dispozici ve free plánu je až 250 GB
- Přehled volných minut – ve free plánu máme 120 minut první měsíc a pak dalších 60 minut každý měsíc.
120 minut je dostatečná doba na hraní, případně iniciální nastavení menšího projektu. Já jsem během této doby stihnul nastavit 3 flows (pipelines), které mi odčerpaly při testování cca 30 minut. Zbytek doby mi vzal Python workspace, u kterého jsem nevěděl, že mi odčerpává minuty, takže jsem si musel dokoupit minuty, abych mohl pokračovat v testování.
Flows – Data flows/pipelines/datové toky v Keboole
Položka v menu flows obsahuje všechny datové toky nebo pipelines v (Keboole to nazýváme Flows). Datové flow se skládá z komponent (components). Jak vidíme na screenshotu dole, mám již vytvořeny 3 flows. Jednotlivá flows lze ukládat do adresářové struktury. Vidíme, že máme k data flows i nějaké základní charakteristiky
- Scheduled – jestli je data flow naplánováno na pravidelné běhy
- Last change – datum poslední změny
- Run results – jak dopadlo posledních 10 spuštění flow
- Last use – kdy bylo naposledy spuštěno flow
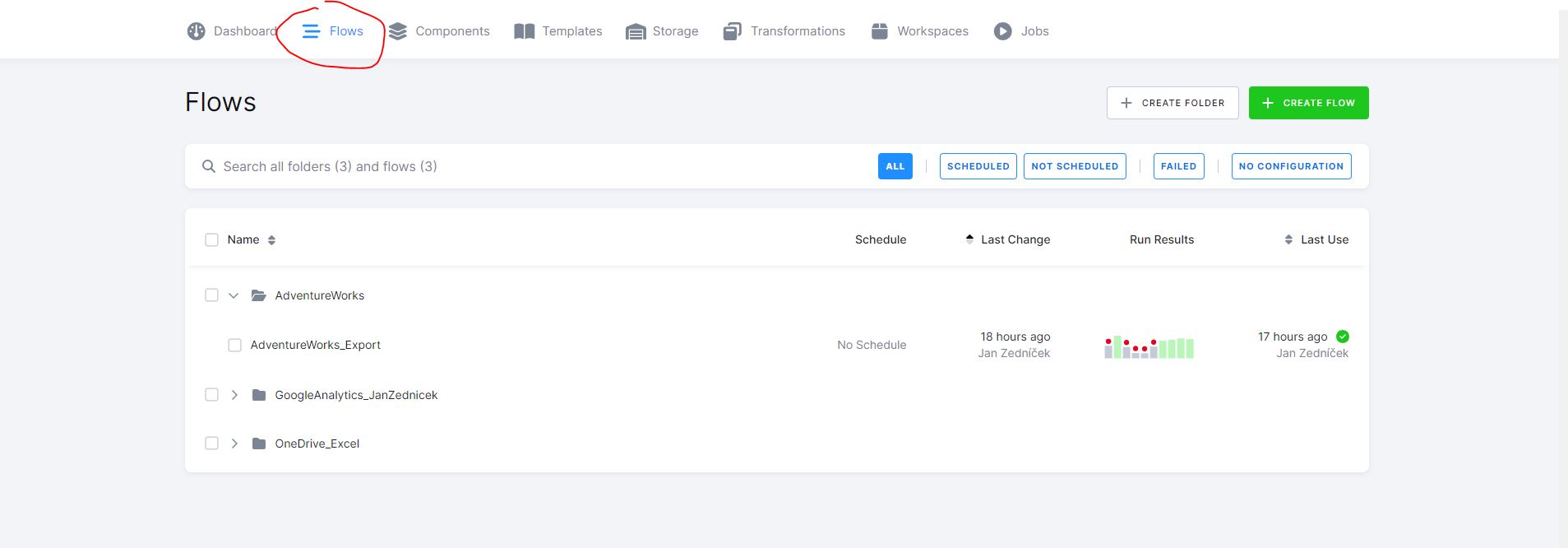
Pokud kliknu na nějaké flow, tak mě to zavede do detailu data flow kde máme nadefinované komponenty (viz dále) na naše datové zdroje a destinace a vazby mezi nimi. V případě data flow nazvaného AdventureWorks to vypadá viz níže.
Podrobnější informace o flows viz článek – ETL | Keboola – Data Flow návod – SQL Server do Google drive

Komponenty (components) – datové zdroje a destinace v Keboole
Na stránce s komponentami (components) vidíme všechny konfigurace na datové zdroje a destinace. Komponenty jsou bloky, ze kterých se skládá kromě jiného flow. Flow může obsahovat i jiné bloky – např. transformace, ale mělo by obsahovat vždy komponentu typu a) zdroj – source a b) cíl – destination.
Jak vidíte, tak já mám pár komponent již nadefinovaných – Google analytics, One drive, aj. Každou komponentu je potřeba nakonfigurovat – to je říct jí kam vede (na můj účet google analytics apoid). Tento proces je ale s Keboolou velmi jednoduchý, protože Keboola obsahuje přes 200 (free účet) předdefinovaných komponent na různé systémy.

Pokud bychom kliknuli na Add component (přidat komponentu), tak nás aplikace zavede do rozhraní kde si můžeme vybrat z velkého množství komponent. Poté co si komponenty nastavíme, můžeme je přiřadit do flow.

Templates – předpřipravená data flows v Keboole
V této sekci najdeme předdefinované flows. Pokud klikneme na nějaký template, tak se nám otevře nastavení flow, dke je ptořeba povyplňovat konfiguraci. Vyzkouším v nějakém dalším článku.

Storage buckets (omezení 250 GB) v Keboole
Další stránka je zajímavější. Na karte storage vidíme naše soubory, které jsou umístěny do buckets což jsou kontejnery nebo úložiště pro soubory. Máme v zásadě 2 typy bucketů v Keboole a to jsou
- IN bucket/soubor – zde se ukládají soubory jako výsledek extrakcí
- OUT bucket/soubor – zde se ukládají soubory jako výsledek transformací – data která vstupují do transformací jsou typu IN a co dostaneme ven je OUT

V každém bucketu jsou soubory:

Každý soubor má svoji stránku s náhledem na data, statistiky a charakteristiky. Na storage uděláme separátní článek.

Transformations – transformační úlohy v data flows
Na stránce transformace evidujeme další skupinu bloků, ze kterých je možné skládat flow. Jak jsem již psal, ve flow je potřeba mít povinně a) source b) destination. Někdy ale chceme data před uložením do cílového úložiště transformovat a to se dělá právě tady

Pokud chceme založit novou transformaci, tak klikneme na Create transformation a transformaci vytvořime podle toho co je nám milejší
- Python
- R
- Snowflake
- No-code
- dbt-core transformation

Keboola testovací vs produkční environment
V Keboole můžeme vytvořit více různých prostředí (typicky pro testovací účely). V horní části obrazovky máme možnost kliknout na “New development branch”

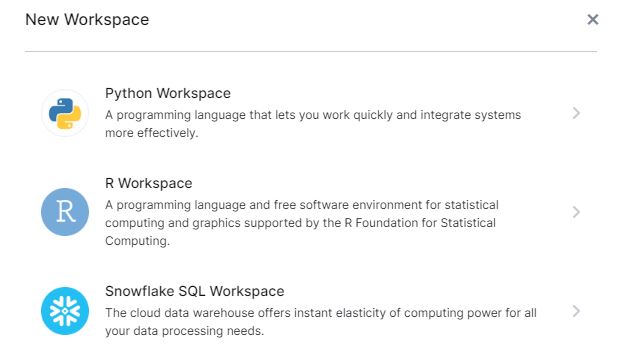
Workspaces v Keboole
Poslední sekcí v menu jsou workspaces, kdy se nám po založení vytvoří prostředí dle výběru. Pozor na vytváření Python a R workspaces pro testovací účely – viz varování na screenshotu. Tyto prostředí jsou zpoplatněna a po dobu aktivity vám budou strhávat minuty.
Na výběr máme ze 3 typů – Python, R a snowflake.