

V minulém článku, který byl věnován seznámení s Mage.ai – nástrojem pro tvorbu a správu ETL procesů jsem na konci sliboval, že si v dalším článku zkusíme vytvořit s Mage.ai pipeline – tedy datový tok. Pokud tento ETL framework neznáte, tak doporučuju proletět úvodní článek.
Zdrojová a cílová databáze pro ETL pipeline
V tomto cvičení budeme mít za úkol vytvořit pomocí Mage.ai ETL proces, který zkopíruje tabulku “Address” z jedné instance na druhou, žádné transformace – prostě jednoduše 1:1. Nejprve se tedy pojďme podívat, odkud kam budeme dělat datovou ETL pumpu.
Zdrojová (Source) tabulka a databáze pro ETL – Adventureworks Azure
Zdrojem pro nás bude veřejně dostupná databáze Adventureworks, kterou provozuje sqlcentralcom. Tato OLTP databáze leží v Azure a obsahuje několik tabulek viz screenshot. Nás bude pro účely ETL pipeline zajímat zatím pouze tabulka
- Instance: sqlservercentralpublic.database.windows.net
- Databáze: AdventureWorks
- Schéma: SalesLT
- Tabulka: Address
Dodatečné údaje – port klasika 1433, username sqlfamily, password: viz odkaz na sqlcentralcom.

Zdroj tedy známe a máme vše co potřebujeme k tomu, abychom sestavili připojovací řetězec (connection string)
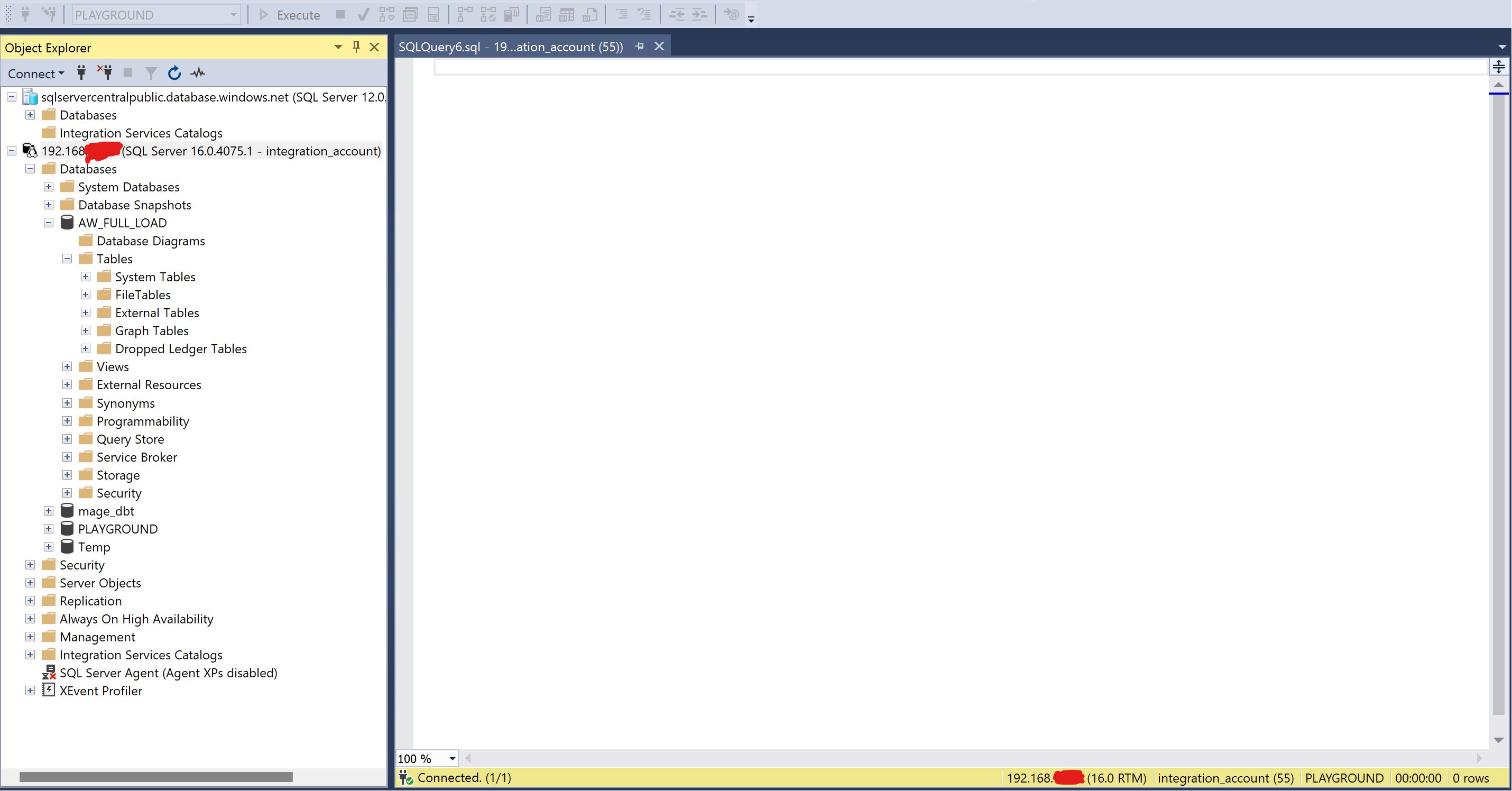
Cílová (Destination) databáze pro ETL – Data Warehouse
Pod cílovou databází si představíme datový sklad – ten je pro ilustrační účely provozován na:
- Macbook M1 Air 16GB RAM s Windows běžícím přes Parallels
- SQL server běží přes Docker na iOS
- Mage.ai instance běží na iOS
SQL Server a mage.is spravujeme ve Windows přes Management studio a prohlížeč.
- Host: 192.168.XXX.XXX
- Databáze: AW_FULL_LOAD
- Port: 1433
- Cílová tabulka: FL_ADVENTUREWORKS_ADDRESS
- login integration_account
- pass *****
Tak máme vše co potřebujem
Vytvoření ETL pipeline v Mage.ai
Vytvoření ETL se bude skládat z několika kroků, nejprve budeme muset
- Nakonfigurovat nové datábáze v souboru io_config.yml – hesla mít nechceme v konfiguračním souboru, takže v Mage využijeme funkce pro správu secrets a v konfiguráku na ně odkážeme.
- Následně vytvoříme novou pipeline a do nové pipeline přidáme 2 bloky
- data_loader – napojí se na naši zdrojovou databázi a stáhne data
- data_exporter – napojí se na cílovou databázi a nahraje tam data
- Celou pipeline spustíme a zkontrolujeme
Toto nastavení budeme muset pochopitelně absolvovat pouze jednou pro nový zdroj nebo cíl dat.
Konfigurace souboru io_config.yml v Mage.ai
Zapneme webserver mage a podíváme se jak soubor vlastně vypadá. Vidíme, že po instalaci Mage.ai jsou v souboru nějaká vzorová nastavení a že tato nastavení jsou pod profilem default

Tento profil je “skladiště templates”. Vyhledáme si sekci MSSQL kterou zkopírujeme a vložíme na konec a úpravou parametrů vytvoříme spojení na naše servery. Vytvoříme si pro každy server nový profil. Vidíme, že jsem založil 2 profily – jeden pro adventureworks a druhy pro data warehouse

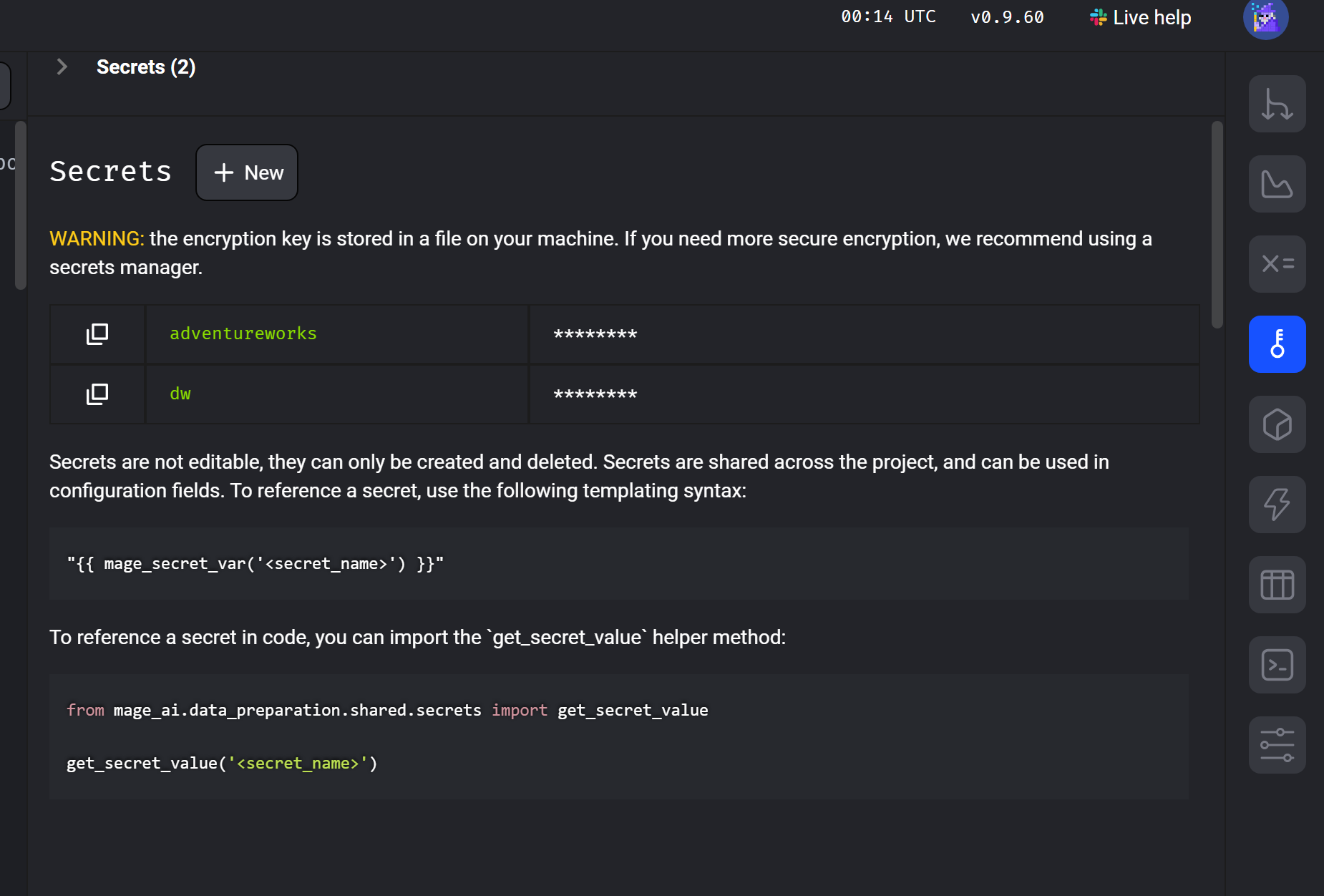
Možná jste si všimli, že v konfiguračním souboru nemáme hesla – to nikdy nechceme. Šli jsme v aplikaci do Secrets a založili si 2 nové secrets. Na které pak odkážeme v konfiguračním souboru.
Vytvoření data_loaderu v pipeline
Nejprve půjdeme do sekce pipelines a vytvoříme novou pipeline – typ standard batch. Tu si nějak později vhodně pojmenujeme abychom se v tom vyznali.

Po založení pipeline nás to vezme do prostředí kde se vytváří bloky – tedy naše data_loadery a data_exportery. Nejprve vytvoříme blok který se připojí na naše zdrojová data.
Klikneme na Data loader – python – databases – MSSQL

Po založení dataloaderu nás to vezme to definice pipeline a vidíme, že vpravo máme nový blok. Současně se nám otevřelo okno k tomuto bloku s Pythonem. Jak vidíte je ale vše připraveno a je potřeba pouze kód lehce upravit, nemusíme jej psát – to za nás zařídil Mage.ai.
Jediné 2 věci které upravíme je query a config_profile.

Jako config_profile zvolíme náš profil z konfiguračního souboru: AdventureWorks a do query napíšeme dotaz na naši tabulku

Otestujem, jestli se dat načtou – vypadá to okej

Vytvoření data_exporter v Mage.ai
V předchozím kroku máme blook, který umí naimportovat data. Nyní si musíe připravit blok, který tato data nahraje do naší cílové databáze. To je ještě jednodušší než u data_loaderu. Klikneme na přidat Data exporter a opět lehce editujeme předpřipravený Python skript

Data_exporter můžeme spustit a podívat se jestli dojede -vše je ok

ETL Mage.ai pipeline by měla být nastavena a ready to go
Spuštění Mage pipelina a test dat
Je čas na malý test. Zkusíme se spustit Mage pipeline z aplikace a pak se podíváme do cílové destinace v datovém skladu jestli tam jsou data.
Pipeline můžeme spustit například tak, že ji spustíme jednorázově. Další varianta je udelat schedule a v tomto případě se nám pak bude toto ETL spouštět v předem určený čas. My s ji spustíme jednorázově na screenshotu níže – vidíme. že pipeline v úspěšně skončila
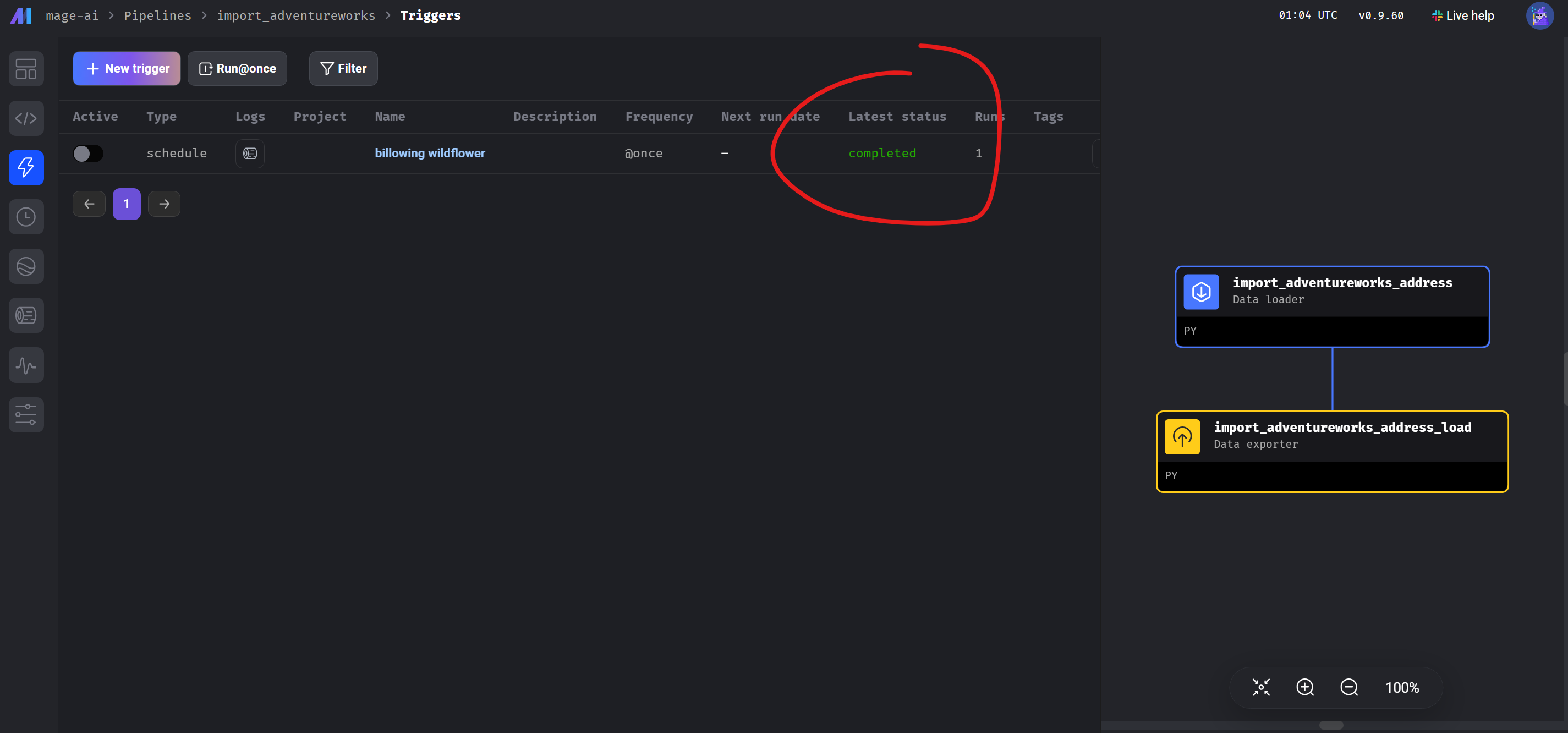
V databázi imaginárního datového skladu máme nová data:
